1. Résumé
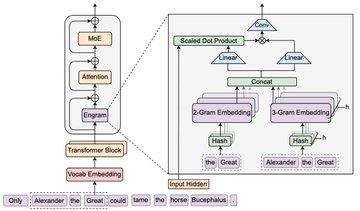
Engram est un module open source de « mémoire conditionnelle » de DeepSeek, et l’idée centrale est d’ajouter une primitive mémoire extensible de recherche de forme au Transformer : une partie du motif/connaissance plus statique est stockée sous forme d’une table mémoire N-gramme, récupérée de manière approximative O(1) lors de l’inférence, puis fusionnée avec l’état caché actuel. La conclusion donnée par le dépôt officiel est que, sous les contraintes de paramètres et de puissance de calcul égales, Engram-27B a des rendements stables comparés à la base du MoE dans des tâches telles que la connaissance, le raisonnement, le code et les mathématiques. Et l’analyse des mécanismes montre qu’elle peut réduire la charge de la « reconstruction » du modèle statique dans la couche initiale, de sorte que la profondeur effective est destinée à des calculs d’inférence plus complexes.
2. Caractéristiques principales
1. Mémoire de condition forme O(1)
Par l’adressage et la récupération déterministes de mémoire statique à N-grammes, la « recherche de connaissances » est partiellement séparée de l’informatique neuronale dense, réduisant ainsi l’occupation du chemin de calcul.
2. « Nouvel axe clairsemé » complémentaire au MoE
Le MoE augmente la capacité par le calcul conditionnel, et Engram augmente la capacité par la mémoire conditionnelle : l’un est « calculé » et l’autre « vérifié », ce qui peut être plus efficacement alloué aux capacités du modèle sous les mêmes FLOP après combinaison.
3. La loi de l’échelle en U est utilisée pour l’allocation de capacité
Le compromis officiel entre « Capacité de calcul (MoE) et Capacité de mémoire statique (Engramme) » est donné, et souligne qu’il existe une loi d’échelle en forme de U qui peut guider les compromis d’ingénierie.
4. L’explication du mécanisme est plus proche de l’intuition technique
Le dépôt mentionne explicitement qu’Engram peut éliminer le besoin des premières couches de reconstruire à répétition des motifs statiques, laissant le nombre de couches et de capacités de représentation aux processus d’inférence plus critiques ultérieurs, ce qui peut être compris comme un « approfondissement plus efficace pour l’inférence ».
5. Efficacité du système et facilité d’atterrissage
L’adressage déterministe est utilisé pour transférer les tables embarquées à hyperéchelle vers la mémoire hôte, et l’augmentation de la surcharge d’inférence est maintenue aussi contrôlable que possible.
3. Installation
1. Préparer l’environnement
Python 3.8+, un environnement isolé (venv/conda) est recommandé.
2. Dépendances d’installation
Démarrage rapide par dépôt : installez des dépendances telles que torch, numpy, transformers, sympy, etc.
3. Organiser la démonstration
Le dépôt fournit des engram_demo_v1.py pour démontrer les flux de données centraux d’Engram ; Cette version simulera certains composants standards (par exemple Attention/MoE, etc.) et mettra en avant le fonctionnement des modules Engram.
4. Cas d’usage typiques
1. Questions et réponses intensives en connaissances et rappel factuel
Lorsque la tâche repose davantage sur un « mode de connaissance stable / expression fixe », la mémoire de recherche peut réduire la reconstruction répétitive du modèle dans les premières couches.
2. Réutilisation stable des fragments dans un contexte long
Des résultats de mémoire statique pour des fragments courts récurrents (phrases fixes, modèles de code, formats courants) afin de réduire les calculs invalides dans de longs contextes.
3. Structure modèle de code et scénarios mathématiques
Dans les tâches avec plus de « routines de dérivation courantes/squelettes de code », les canaux mémoire sont utilisés pour réaliser des structures plus statiques, et les canaux de calcul se concentrent sur la combinaison et le raisonnement.
4. Expansion rentable combinée au ministère de l’Éducation
Sous le postulat que les paramètres totaux et les FLOP totaux sont limités, « une partie de la capacité est placée dans la table de mémoire statique » en échange d’une densité de capacité effective plus élevée.
5. Écologie et produits concurrents
1. Statut écologique
Actuellement, le dépôt officiel est principalement basé sur des articles + diagrammes de structure + diagrammes expérimentaux + démonstrations, ce qui convient à une compréhension rapide du nouveau composant de la « mémoire conditionnelle » et à l’évaluation de l’espace de combinaison avec la pile MoE existante.
2. Produits concurrents et directions adjacentes
Les idées voisines incluent généralement : RAG (Amélioration de la récupération externe), kNN-LM/Récupération par voisins plus proches, Mémoire en cache traditionnelle N-gram/cache, et diverses architectures de routage à attention parcime/clairsemée. La différence d’Engram est qu’il utilise une « table de mémoire statique entraînable » comme primitive interne du modèle, et met l’accent sur la division du travail et l’échelle avec MoE. L’effet réel doit encore être vérifié en combinaison avec une distribution spécifique des données, une formule d’entraînement et des contraintes de déploiement.
6. Limitations et précautions
1. Détails et qualité de reproduction du journal
Le dépôt fournit des conclusions clés et des démonstrations, mais les détails de la formation à grande échelle, de la mise en œuvre de l’intervention et de l’ablation complète doivent toujours être basés sur l’article.
2. Compromis entre la mémoire et le déploiement
Transférer d’énormes tables mémoire à la mémoire hôte réduit la pression mémoire, mais introduit de nouvelles contraintes sur la bande passante, la latence et la complexité d’ingénierie.
3. L’applicabilité dépend de la forme de la tâche
Si le principal goulot d’étranglement de la tâche est le « raisonnement dynamique/généralisation combinatoire » plutôt que la « réutilisation statique du mode ou des connaissances », les bénéfices peuvent ne pas être aussi évidents que les tâches à forte intensité de connaissances.
4. Coût d’intégration avec le système d’entraînement existant
Pour connecter de nouveaux modules à la mise en œuvre du MoE/attention existante et aux stratégies parallèles, il faut évaluer la stabilité de l’entraînement, le débit et les indicateurs de suivi (tels que le taux de réussite, l’utilisation de la capacité de la table, etc.).
7. Adresse du projet
https://github.com/deepseek-ai/Engram
8. Questions fréquemment posées
Q : Quels sont les mots-clés clés d’Engram et quels problèmes résout-il ?
R : Les mots-clés sont mémoire conditionnelle, recherche évolutive, mémoire de recherche O(1) et mémoire N-gramme. Il essaie de donner au transformateur la capacité de « recherche native de connaissances » pour séparer certains schémas/connaissances statiques du calcul intensif.
Q : Quelle est la relation entre Engram et MoE ?
R : Le MoE augmente la capacité par le calcul conditionnel, et l’Engramme augmente la capacité via la mémoire conditionnelle. Les deux peuvent se compléter pour former une division du travail : « calcul (calcul) + vérification (mémoire) ».
Q : Que signifie l’analyse mécaniste officielle par « plus efficace et plus profonde » ?
R : La vision du dépôt est qu’Engram réduit la charge de reconstruire des motifs statiques aux premières couches, en rendant la profondeur du réseau plus axée sur les inférences complexes ultérieures, ce qui revient à « laisser de la profondeur pour les parties clés ».
Q : Comment puis-je vérifier rapidement comment fonctionne Engram ?
R : Pour exécuter directement les engram_demo_v1.py fournis par l’entrepôt, il faut d’abord comprendre le flux de données et la localisation de la fusion. La démo se moque des composants courants pour mettre en avant Engram.
Q : Engram est-il adapté comme alternative à RAG ?
R : Il est plus adapté comme direction complémentaire : RAG est la récupération et la mise à jour externe de documents, et Engram est un langage primitif interne de mémoire statique et division du travail informatique/mémoire. La substitution dépend de la nécessité de savoir si la tâche nécessite une connaissance externe à jour et un lien de récupération contrôlable.



