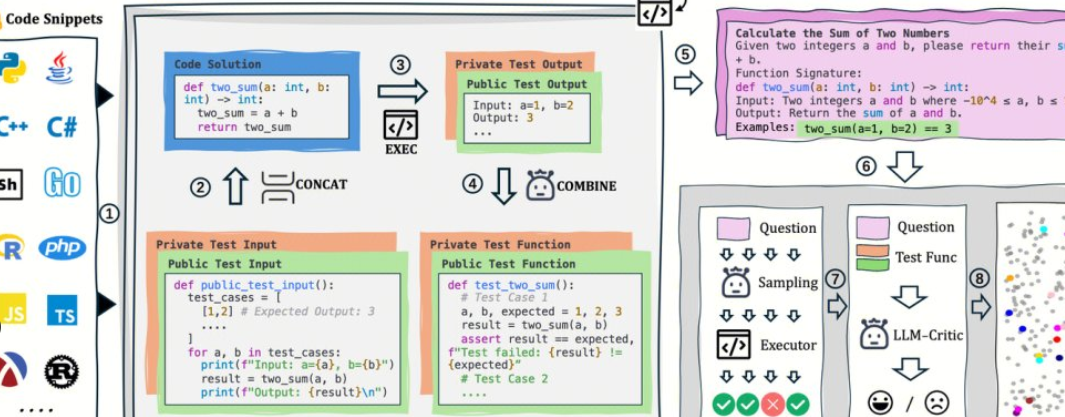
AutoCodeBench is open-sourced by Tencent's Hunyuan team, and its core is an automated workflow of "LLM generation + multilingual sandbox validation". The project also open-sources AutoCodeGen (data synthesis), AutoCodeBench (three sets of benchmarks, Full / Lite / Complete), and MultiLanguageSandbox (30+ language sandboxes) to evaluate the multilingual coding capabilities of Base and Chat models, and support self-generation of new benchmarks.
1. Project Overview and Value
- No manual annotation: LLM is used to synthesize questions and reference answers, and verifiable standard outputs are automatically generated through the sandbox.
- Multilingual and difficult: Covering 20 programming languages and 3,920 practical problems, the difficulty layering is closer to real development.
- Evaluation and data are the same source: the same process can not only generate data, but also play back the evaluation, which is convenient for reproducibility and horizontal comparison.
2. Open source address
1. Project homepage: https://autocodebench.github.io
2. Paper: https://arxiv.org/abs/2508.09101
3. Codebase: https://github.com/Tencent-Hunyuan/AutoCodeBenchmark
4. Dataset: https://huggingface.co/datasets/tencent/AutoCodeBenchmark
3. Data and benchmark composition
- Full: 3,920 questions, covering 20 languages, emphasizing difficulty and diversity.
- Lite: 1,586 questions, screened by cross-model "solvability", which is more conducive to quick comparison.
- Complete: 1,000 questions, 3-shot setting, code completion evaluation for the Base model.
- Language and difficulty: Balanced sampling according to language, the difficulty is divided into easy/medium/hard, taking into account both breadth and intensity.
4. Evaluation paradigm and indicators
- Unified instructions: require the output of a single code block, without running commands and examples.
- Sandbox verification: Compile/run the generated code topic-by-topic, calculate objective indicators such as pass@1.
- Two-line evaluation: Simultaneously covers Chat generation and Base completion to reduce the bias of "only testing the dialogue model".
5. Get started quickly (5 steps)
1. Prepare the output: Use your model to generate code for questions in autocodebench.jsonl question by question and save it as model_output.jsonl.
2. Pull the image: docker pull hunyuansandbox/multi-language-sandbox:v1.
3. Start the service: docker run -d --name sandbox -p 8080:8080 hunyuansandbox/multi-language-sandbox:v1.
4. Health check: Submit the minimum sample to POST /submit to confirm that the compilation/execution is normal.
- Calculation metrics: Use warehouse scripts to call sandboxes in batches, generate execution results, and count pass@1.
6. Typical applications and applicable groups
- Model team: cross-language regression and version comparison, locate compilation failure/boundary use cases.
- Scientific research evaluation: Build high-quality multilingual benchmarks at low cost to improve reproducibility.
- Enterprise internal testing: Use Lite/Complete to do grayscale evaluation, observe stability and long-tail questions.
7. Practical suggestions
- Lite first and then Full: Quickly screen first, and then do a comprehensive regression and report.
- Concurrency and quotas: Sandbox compilation/running is a bottleneck, and it is recommended to schedule queues and implement them in a distributed manner.
- Observability: Failure of record by type (compilation/run/boundary/time limit), targeted optimization prompts and hyperparameters.
- Cooperate with RAG: Long questions and cross-file tasks are combined with search enhancements to enhance stability.
8. Limitations and risk warnings
- Environmental consistency: Mirroring and dependencies will affect the pass rate, and it is necessary to lock the version and random seeds.
- Data compliance: When the topic and code involve external databases, it is necessary to do a good job of isolation and auditing.
- Extrapolated boundary: The benchmark score is not equal to production availability, and real business sample A/B is still required.
9. Frequently Asked Questions
- Is it really "fully automatic and zero manual annotation"?
The process is centered on LLM generation and sandbox verification, and does not rely on manual annotation on a topic-by-topic basis. Manual sampling of key samples is recommended to check the quality.
- What languages are supported, and is it biased towards Python?
The sandbox supports 30+ languages and covers 20 programming languages with data balancing, significantly reducing the "Python only" bias.
- How to evaluate Chat and Base at the same time?
Chat generates code directly from unified system prompts; Base uses Complete's 3-shot completion settings to keep the evaluation protocol consistent.
- Can I use the same workflow to generate custom baselines?
OK. AutoCodeGen automatically synthesizes new questions and test sets in a sandbox using the same verification and scoring process.



