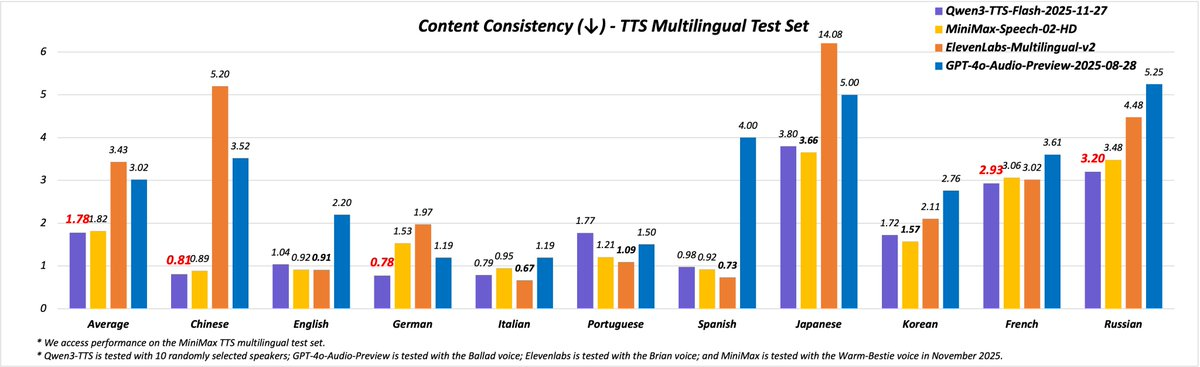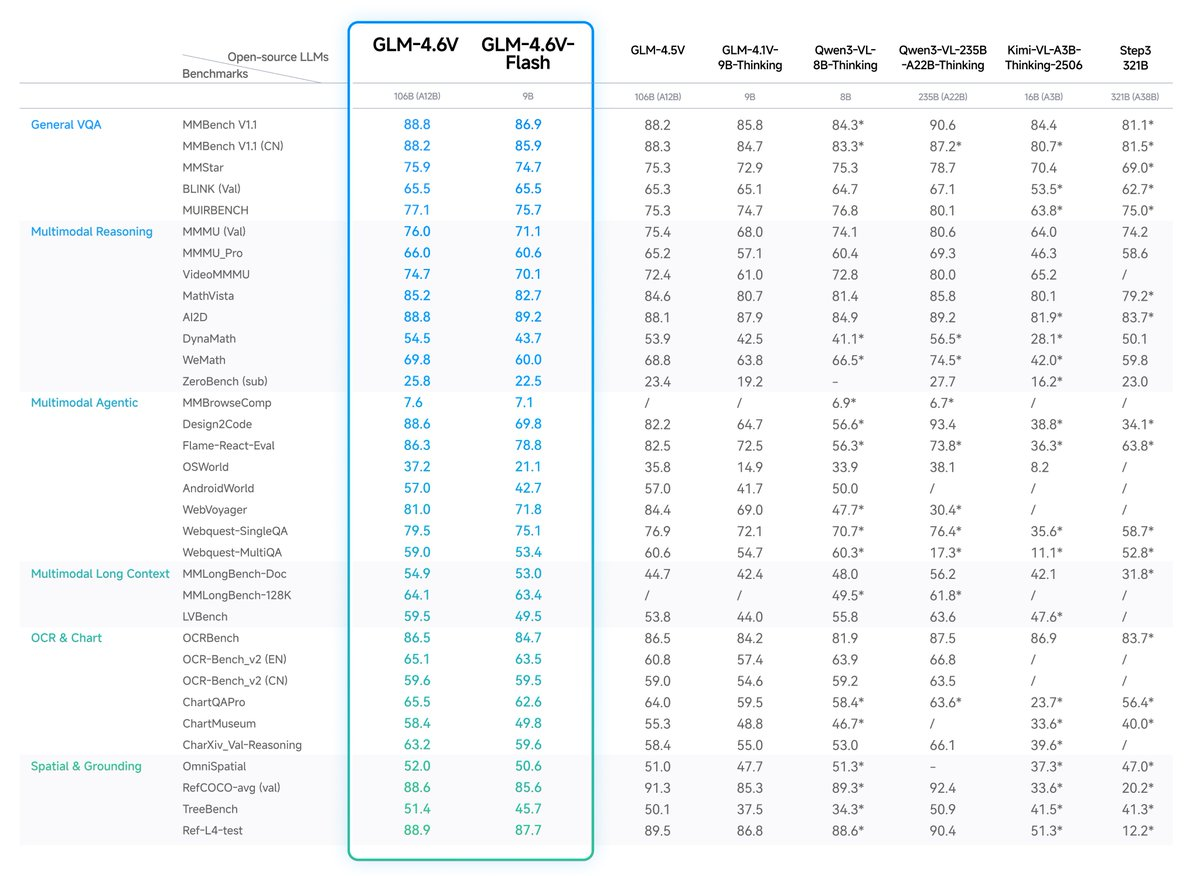
Zhipu's platform Z.ai announced the launch of the GLM-4.6V series of visual language models, including GLM-4.6V for cloud and high-performance cluster scenarios with a parameter scale of 106B, and a lightweight version of GLM-4.6V-Flash for local and low-latency scenarios. According to the official introduction, GLM-4.6V supports up to 128K token context in training, can process multimodal inputs such as images, text, and files at the same time, and achieve high visual understanding capabilities in models of the same size.
In terms of capability design, the GLM-4.6V series integrates native function calling capabilities into the family of vision models for the first time, which can trigger tools or business interfaces based on understanding images and long documents, providing infrastructure for multimodal agent applications. Developers can experience the model through the online dialogue page provided by Z.ai, or use the API interface to integrate calls in their own businesses. At the same time, model weights are open to the public on Hugging Face, making it convenient for teams with computing power to deploy locally or privately.
In terms of fees, the API billing announced by Z.ai is calculated in million tokens, GLM-4.6V cloud inference is billed separately for input and output, and the Flash version is currently marked as free, which is suitable for cost-sensitive and latency-sensitive application scenarios. The specific price, limited-time offer, and quota rules are subject to the developer documentation and console publicity, and users need to pay attention to account quotas, security compliance, and privacy protection issues for multimodal data uploads before accessing.
FAQs
Q: What model is GLM-4.6V?
A: GLM-4.6V is a multi-modal large model launched by Z.ai, which can simultaneously process inputs such as images and text, and supports long context and reasoning capabilities.
Q: What is the difference between GLM-4.6V-Flash and GLM-4.6V?
A: GLM-4.6V-Flash is a lightweight and high-speed version, which is more suitable for on-premises deployment and low-latency applications, while GLM-4.6V is suitable for cloud and high-performance cluster scenarios.
Q: How can I experience the GLM-4.6V series models?
A: Regular users can experience it through Z.ai's online chat page, and developers can integrate it into their own apps through the official API.
Q: Does the GLM-4.6V support function calls?
A: The GLM-4.6V series supports native function calls, which can be used to call external tools or business interfaces after parsing images and documents, making it easy to build multimodal agents.
Q: What is the price of GLM-4.6V and GLM-4.6V-Flash?
A: GLM-4.6V is billed for API calls on a million-token basis for input and output, and GLM-4.6V-Flash is currently marked as free, according to the official pricing page.