1. Abstract
LongCat-Image is an open-source bilingual image generation and editing model in Chinese and English by Meituan's LongCat team, with parameters of about 6B, using a hybrid DiT architecture, which is comparable to or even exceeds some 20B level open source models in many public benchmarks. The project focuses on improving multilingual text rendering, image consistency, and realistic effects, and takes into account inference speed and video memory occupation, making it suitable for research and business implementation.
2. Core features
- Bilingual text capability in Chinese and English: Special optimization for complex Chinese Chinese characters (including rare characters), and outstanding performance in Chinese text rendering indicators.
- Unified generation and editing: Provide LongCat-Image, LongCat-Image-Dev, LongCat-Image-Edit and other versions, covering tasks such as textual images, whole/partial editing, and text modification.
- Lightweight and efficient inference: 6B hybrid DiT architecture supports low-precision inference, balancing speed and quality on limited video memory.
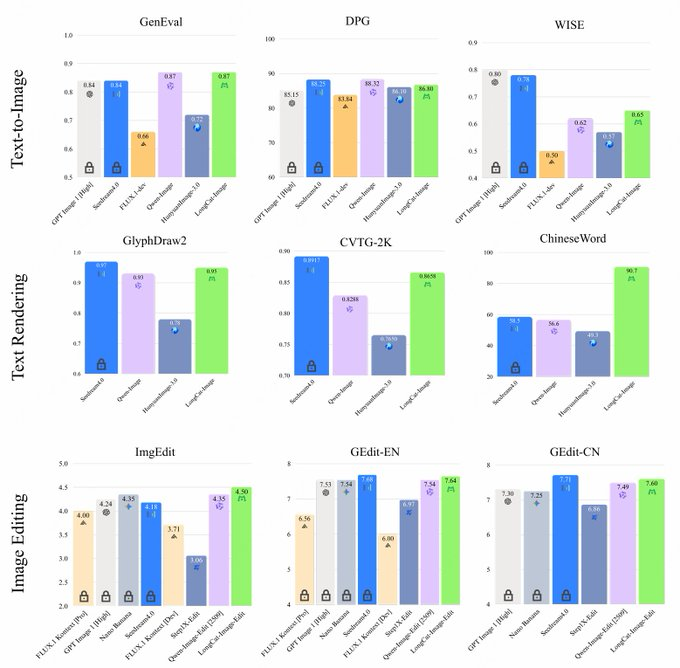
- Realism and alignment: Combined with data strategy and RL training, it enhances the alignment of object structure, style and instructions, and is in the same echelon as the head model on benchmarks such as GenEval and DPG.
- Complete toolchain: Provides training code, examples, and intermediate checkpoints under the open source license, making it easy to continue training, LoRA, and DPO research.
3. Installation
- Environment preparation: It is recommended to use Python 3.10 and NVIDIA GPUs that support CUDA, and it is safer to use video memory from 16–24GB.
- Clone Repository:
git clone --single-branch --branch main https://github.com/meituan-longcat/LongCat-Image
cd LongCat-Image
- Installation Dependencies:
conda create -n longcat-image python=3.10
conda activate longcat-image
pip install -r requirements.txt
__CODE_ INLINE_5__
- Download weights:
Use huggingface-cli to download the LongCat-Image / LongCat-Image-Dev / LongCat-Image-Edit weights from the corresponding repository to the local directory and point to the path in the configuration.
4. Typical use cases
- Chinese/English text graphics: posters, e-commerce maps, operation materials, etc., which require high requirements for Chinese glyphs, typography and theme consistency.
- Natural language image editing: global style replacement, partial modification, object addition and deletion, text content replacement, etc. according to the text.
- Brand visual customization: Combine LoRA or continue training to solidify brand characters, color matching, and composition styles for long-term unified output.
- Academic and engineering baseline: As an open-source baseline for bilingual image models in Chinese and English, validate new losses, new data ratios, or new RL strategies.
5. Ecology and competing products
- Ecology: Officially provide training pipelines, inference scripts, and gradually integrate with Diffusers, ComfyUI and other ecosystems to facilitate access to existing AIGC processes.
- Comparison of competitors: Compared with models such as Qwen-Image, HunyuanImage, Seedream, and FLUX, LongCat-Image has obvious advantages in Chinese text rendering and editing benchmarks, with smaller parameters and lower deployment thresholds. The specific effect still needs to be combined with business data and subjective evaluation.
6. Limitations and precautions
- Computing power requirements: High resolution generation and multi-step editing still require high video memory, and small video memory devices need to reduce resolution, number of steps or batch size.
- Language and scene range: Mainly optimized for Chinese and English, other languages or extreme visual scenes may perform unstable.
- Content compliance: The model may generate inappropriate content, and the actual deployment needs to cooperate with security audits, keyword filtering, and manual review.
- Uncertainty outside the benchmark: Public benchmark results do not fully represent the performance of business scenarios, so it is recommended to conduct A/B testing and manual quality inspection.
7. Project Address
https://github.com/meituan-longcat/LongCat-Image
8. FAQs
Q: What core tasks does LongCat-Image support?
A: It supports bilingual text-to-image generation, whole/partial image editing, text content modification, reference image constraint editing, etc., and different versions have their own emphasis on generation, development, debugging, and editing tasks.
Q: How much video memory does LongCat-Image inference require?
A: The official does not give a hard lower limit, and the general experience is that a single card can run regular resolution tasks with 16–24GB of video memory; For high resolution or batch generation, you can use multiple cards or reduce the resolution and number of steps.
Q: What are the advantages of LongCat-Image in Chinese text generation?
A: It outperforms many open-source models in benchmark indicators such as Chinese character accuracy, complex glyph restoration, and image and text consistency, while taking into account the overall image quality and readability.
Q: Is LongCat-Image easy to continue training or LoRA fine-tuning?
A: Yes. The project has an open training toolchain and an intermediate checkpoint that can be used for SFT, LoRA, DPO, and editing training, but requires the preparation of corresponding computing power and high-quality datasets.