I. Abstract
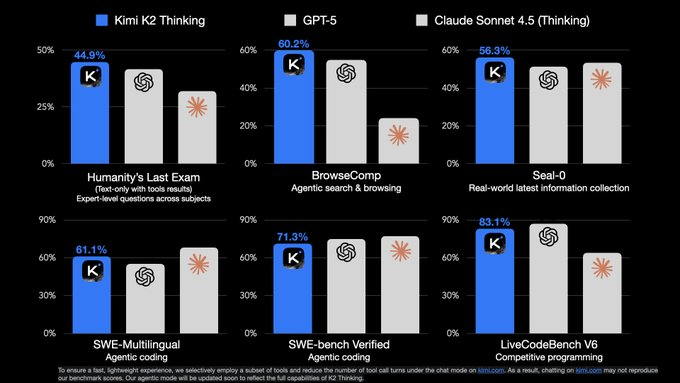
Kimi K2 Thinking is an open-source "thinking" intelligent agent model launched by Moonshot, emphasizing dynamic tool invocation and multi-step planning during the inference process. Officially, it achieves 44.9% HLE and 60.2% BrowseComp, can stably complete 200-300 consecutive tool invocations, and supports 256K context and native INT4 quantization, targeting deep retrieval, encoding, and complex task decomposition.
II. Core Features
1. Agentic reasoning : a closed loop of thinking—searching—reading—executing, maintaining consistency over long and multi-step processes.
2. Toolchain stability : It can maintain 200–300 consecutive calls, reducing mid-way drift.
3. Performance metrics : HLE 44.9%, BrowseComp 60.2% (both with tool context enabled).
4. Engineering-friendly : 256K context and native INT4, making inference latency and VRAM usage more controllable.
5. Multiple entry points : The chat client is now online, the API is available, and the weighting is published on Hugging Face.
III. Installation
1. API method : Create a key on the Moonshot platform and call kimi-k2-thinking as per the documentation.
2. Local inference : pull weights from Hugging Face; can be deployed using Transformers/vLLM; also available through third-party distribution (such as Ollam/FaaS platforms).
3. Tool Integration : Configure tools such as browsers, search engines, and code execution as needed, and set timeout/step limits.
IV. Typical Use Cases
- In-depth cross-site research and abstract integration.
- Data and code collaboration: Read documentation → Write scripts → Verify → Fix.
- Long document/multi-source fact-checking and citation collection.
- Planning and evidence chain tracing in Retrieval Enhanced Generation (RAG).
- Operations and Analysis Automation: Search → Crawling → Cleaning → Reporting.
V. Ecology and Competitors
- Ecosystem: Chat client, open platform API, HF weights and documentation, community tutorials and third-party hosting are synchronized.
- Competitors: Llama, GLM, DeepSeek, and other similar open-source "intelligent agents" each have their own trade-offs in long-term toolchains and retrieval strategies; K2 Thinking's 200+ consecutive calls and INT4 deployment are the differences, and the actual effect will be subject to business verification.
VI. Limitations and Precautions
- Most evaluations are conducted with the tools enabled; offline pure reasoning scores may differ.
- Long links lead to latency and cost accumulation, so it is necessary to limit the number of steps and concurrency.
- Dynamic loading of web pages, anti-scraping measures, and permission-related scenarios may affect stability.
- Automated execution requires compliance and a security sandbox, and important results should be manually reviewed.
VII. Project Address
https://huggingface.co/moonshotai/Kimi-K2-Thinking
VIII. Frequently Asked Questions
Q: Has K2 Thinking opened its API and chat interface?
A: The official platform API has been released, and it can be used directly in the chat client.
Q: What is the significance of 256K context versus INT4?
A: Longer input and lower memory/latency make it suitable for long documents and multi-round toolchains.
Q: Is it possible to deploy and integrate custom tools locally?
A: It can perform local inference and extend browsing/code/search tools, but you need to implement security isolation yourself.
Q: How to control costs when calling tools 200-300 times consecutively?
A: Set maximum steps/timeout, phased planning, and cache search results to reduce redundant overhead.
Q: Can evaluation scores represent the actual business results?
A: It has reference value, but A/B testing and manual quality inspection are still needed in the target scenario.