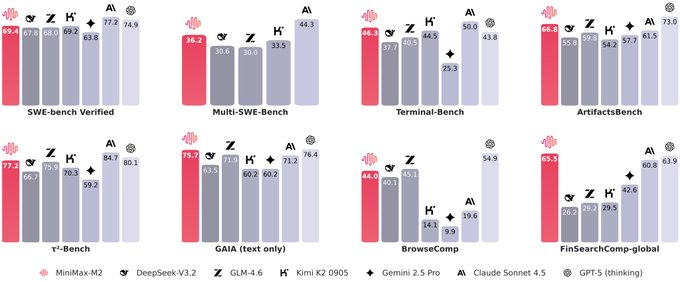
I. Summary
MiniMax M2 is MiniMax's open-source reasoning and programming-oriented model, positioned as "Agent & Code Native." The official introduction states: "Based on the Mixture-of-Experts (MoE) architecture, the model has a total parameter size of approximately 230B, but only activates approximately 10B parameters at a time, thereby maintaining high inference quality while reducing inference cost and latency." MiniMax claims that its performance is close to or comparable to mainstream commercial assistants in code generation, long-chain tool scheduling (shell, browser, search, code execution, etc.), and multi-file modification tasks. It is also priced approximately 8% of Claude Sonnet, with inference speed approximately twice as fast, and is globally free for a limited time in the MiniMax Agent/API. Weights can be directly obtained and locally self-hosted on Hugging Face, or accessed through the official API using an inference interface similar to Anthropic/OpenAI.
2. Core Features
- Developer workflow: Emphasis on "end-to-end", supports reading existing repositories, modifying multiple files, and running-testing-fixing closed loops, targeting IDE/CI/agent-based coding assistant scenarios.
- Agent Native: Built-in tool usage and calling format guidelines, support for on-demand triggering of external tools (such as mcp, shell, browser, search, code execution, etc.), and can maintain target consistency in long task chains.
- Inference Efficiency: MoE is designed to activate only approximately 10 Bytes of parameters for computation, aiming to achieve lower memory usage and higher throughput on consumer-grade and enterprise-level private clusters. vLLM and SGLang are officially recommended for local deployment, and inference hyperparameters (such as temperature = 1.0, top_p = 0.95, and top_k = 20) are provided.
- Long context and multi-round control: Aiming at the "long-term tool chain" rather than single-round question answering, it emphasizes steady-state behavior in complex multi-step tasks (such as continuously debugging the same project).
- Open and commercial: Public weights, MIT-style open source instructions (subject to the actual repository); and provide a free online inference portal for quick evaluation.
3. Installation
- Obtain the model: Download the MiniMax-M2 safetensors weights and config.json from the Hugging Face repository. The model is stored in shards using the MoE structure, so you need to pull all shards completely.
- Inference Engine: Use vLLM or SGLang to start local inference services according to the official guide; both support high concurrency and long context scenarios and are suitable for hosting on enterprise/local GPUs.
- Inference parameters: The official recommendation is temperature = 1.0, top_p = 0.95, and top_k = 20. A chat_template.jinja file compatible with common chat templates is also provided for direct integration into the standard chat/agent loop.
- API method: If you do not want to self-host, you can directly call the text-generation / Anthropics-style API of the MiniMax platform, which is currently officially promoted as "global free for a limited time"; this is suitable for quickly evaluating latency and stability.
- Tool Calling: Refer to the official Tool Calling Guide. The model will output the required tools and their input parameters as structured parameters, which can be executed by an external orchestrator and then the results will be returned.
Typical Use Cases
- Intelligent Coding Assistant: locates bugs in existing code bases, proposes patches, modifies multiple files, and generates/updates test cases.
- Automated Operations and Maintenance Agent: Performs multi-step troubleshooting and information collection through a tool chain such as shell/browser/search, and then summarizes the results.
- Long-term R&D assistance: For example, "build a minimum viable service → generate a Dockerfile → write a deployment script → verify startup logs → fix errors", with the model providing continuous follow-up rather than a single answer.
- Enterprise Private Deployment Assistant: Runs in the company's private warehouse and private dependency environment to meet compliance and privacy requirements while maintaining inference and tool scheduling performance close to commercial quality.
- IDE integration: It can be embedded into autonomous agent-based development environments such as Cursor, Cline, Kilo Code, and Droid for a cyclic "write-run-modify" approach.
5. Ecosystem and Competitive Products
- Ecology:
- MiniMax provides an official agent (MiniMax Agent) and a unified API, allowing M2 to be used directly as an automated development/troubleshooting assistant;
- At the community level, there have been discussions on compatibility requirements for Transformers / GGUF / Apple M-series GPUs (BF16/MPS), indicating that a localized ecosystem is taking shape.
- Competing products:
- Commercial closed-source systems: Claude Sonnet, GPT-4o/4.1 series, etc., are known for their strong code/tool usage, but are usually expensive and closed-source;
- Open-source platforms such as DeepSeek, Qwen, and Llama are rapidly evolving in terms of code and agent capabilities. The MiniMax M2's selling points are "230B total parameters, 10B activations, and near-commercial model behavior," and emphasizes its advantages in inference price and latency. It's important to note that the specific comparison data is mostly official/promotional and based on early benchmarks; actual results must be verified in your own use cases.
VI. Limitations and Precautions
- Actual performance depends on the executor: So-called "high agentic performance" is based on the correct execution and result feedback of external tools. If the execution layer is unreliable, the overall effect will be reduced.
- Vendor claims vs. business reality: For example, "only about 8% of the cost of Claude Sonnet and about 2x faster" is just the official positioning. Cost and latency still depend on hardware, batch size, context length, and concurrency strategy.
- Long-term task consistency: In extremely long, multi-branch tasks, whether the model always remains safe, compliant, and free of destructive instructions still requires additional permissions and audits on the enterprise side.
- Local deployment threshold: Although the activation parameter is about 10B, the total weight scale is 230B MoE shards, which still places requirements on bandwidth, video memory, and loading time.
- Compliance and Data: Using automatic code modification/shell execution in enterprise private scenarios requires strict minimum permissions and audit records to avoid misoperation in the production environment.
7. Project Address
https://github.com/MiniMax-AI/MiniMax-M2
8. Frequently Asked Questions
Q: Is MiniMax M2 truly “open source and commercially available”?
A: The official repository and Hugging Face provide full weights for download, marked as open weights and allowing local deployment. The license is currently described as close to MIT/permissive. Before use, you should still confirm the license verbatim, especially the commercial and redistribution terms.
Q: What is “230B total parameters / 10B activation parameters”?
A: This is a typical MoE (Mixture-of-Experts) approach: the model contains a large number of experts, but only a small number of them are scheduled for each inference. This reduces the computing cost to ~10B while maintaining high capabilities, improving throughput and reducing the unit price of inference.
Q: Does it support tool calling/MCP/browser/Shell calling?
A: The official tool provides a Tool Calling Guide. The model can automatically provide the tools and parameters that need to be called, and can be integrated with external executors such as MCP, Shell, retriever, browser, etc., which is suitable for automated agents.
Q: Can I experience it online without self-hosting?
A: Yes. The MiniMax platform provides the MiniMax M2 API, which is available free of charge for a limited time worldwide. This is suitable for early evaluation and does not require a GPU cluster.
Q: How is it different from Claude Sonnet?
A: MiniMax claims to be close to or even superior to mainstream closed-source models in terms of code, multi-step tool usage, and inference speed. Meanwhile, its inference price is approximately 8% of Sonnet's, and its speed is approximately twice as fast. Please note that these are official benchmarks; actual costs will fluctuate depending on call volume and hardware.