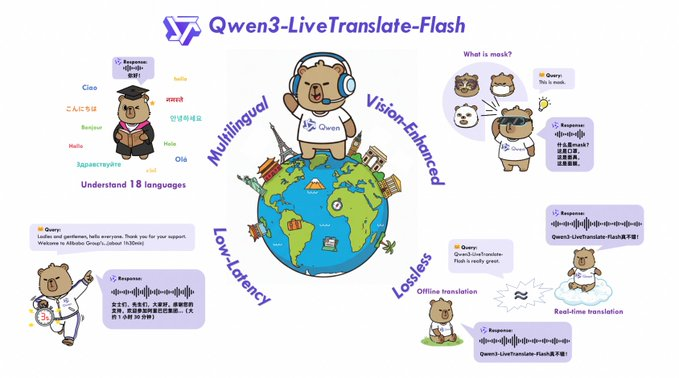
Tongyi Qianwen announced the launch of Qwen3-LiveTranslate-Flash , a real-time multimodal simultaneous interpretation model designed for face-to-face communication and offline events. Official data indicates that the model can complete recognition and translation within approximately 3 seconds of end-to-end latency, recognize 18 languages , understand 6 dialects , and output speech in 10 languages , providing natural and expressive audio. The model emphasizes "visually enhanced understanding" and can combine lip shape, gestures, on-screen text, and entity recognition, maintaining robust performance in noisy environments.
For access, Alibaba Cloud DashScope provides the Qwen3-LiveTranslate-Flash-Realtime interface and rate limit instructions, and offers an online Hugging Face demo for easy experience. Official channels describe it as a real-time interpretation solution with "offline-level accuracy," though specific performance will vary depending on the input device, scene noise, and network conditions. Multi-language coverage and latency metrics are subject to product documentation and subsequent technical reports.
Frequently Asked Questions
Q: What languages and outputs are supported?
A: Recognizes 18 languages, understands 6 dialects, and can output speech in 10 languages; see the Model Studio documentation for a complete list.
Q: What about latency and robustness?
A: The official estimate is about 3 seconds end-to-end. Combining lip reading, gestures, and screen reading can enhance stability in noisy environments. The actual time depends on the device and network.
Q: How to experience or call it?
A: You can experience the demo on Hugging Face; production integration can be achieved through the Realtime interface of Alibaba Cloud DashScope.
Q: Is it open source?
A: It is provided in the form of an API, and its full weight is not currently disclosed; related examples and demonstrations are updated synchronously in the GitHub/HF/ModelScope ecosystem.
Q: What are the applicable scenarios?
A: Real-time applications such as cross-language face-to-face communication, conference interpretation, tourism services, content creation dubbing, and live simultaneous interpretation.