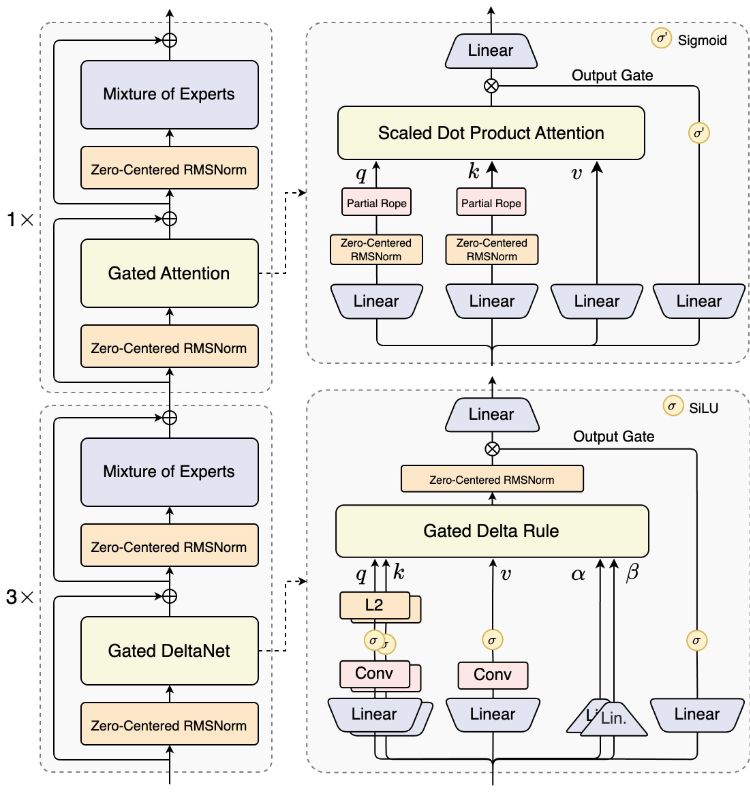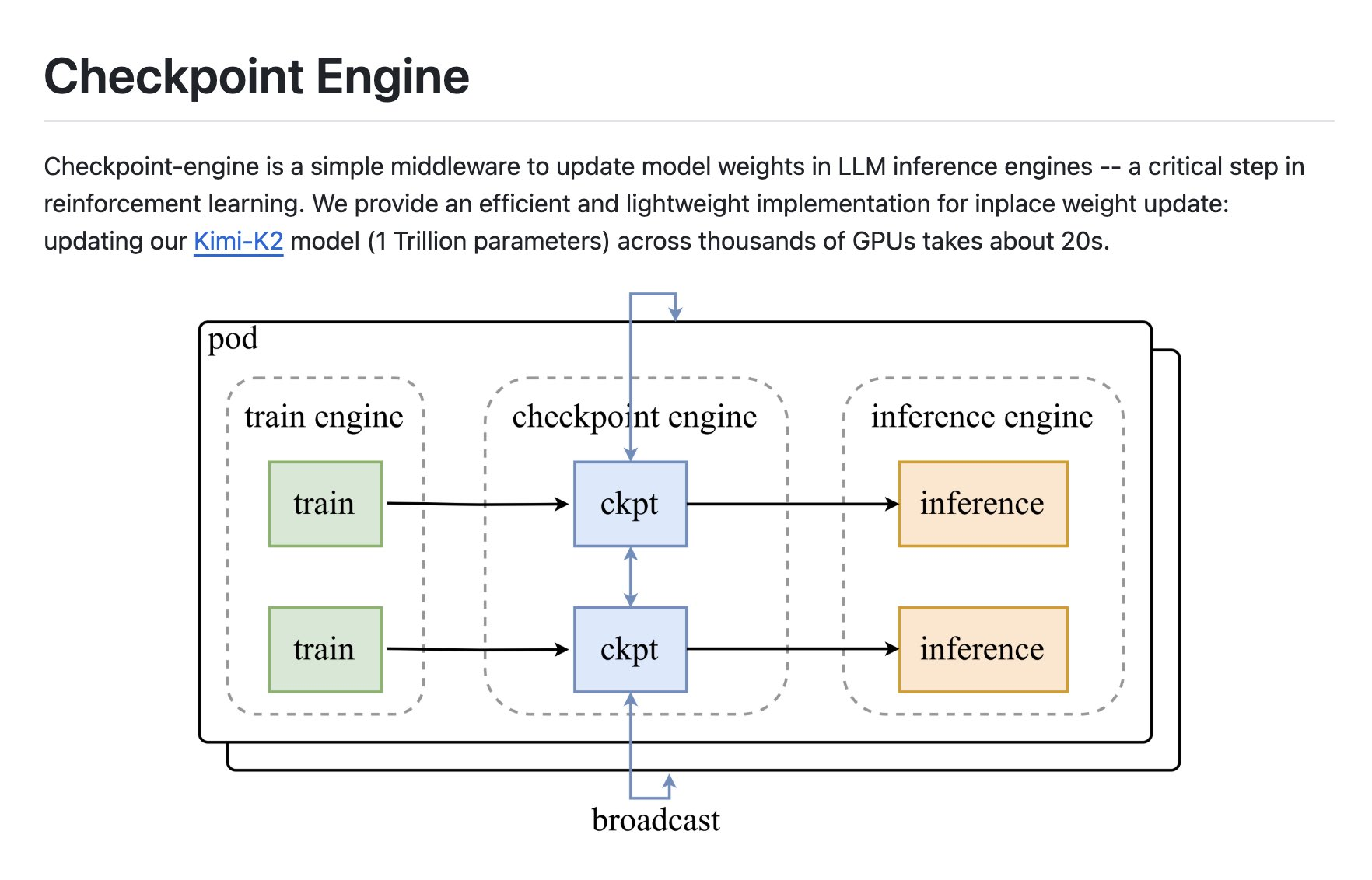
Anthropic publishes an engineering methodology: Design, evaluate, and iterate on tools with AI agents like Claude. The core focus is MCP tooling, systematic evaluation and description optimization, so that agents can take fewer detours, consume less tokens, and get more done.
1. Conclusion first: five iron rules of good tools
1. Choose the right rather than long
AI agents are not developers, and redundant tools will be distracting. Design a small number of high-quality tools around high-value workflows, such as replacing generic lists with search types, to directly align task intent with verifiable outputs.
2. Clear naming and namespace Namespacing
according to service and resource prefixes to reduce overlapping and misuse of tool functions. Different models have different sensitivity to prefix and suffix naming, and the evaluation data needs to be used to determine the scheme.
3. Return the context of "signaling"
Priority is given back to key information and semantic identifiers that can drive subsequent actions, and less low-value fields. Provide detailed and streamlined response_format when necessary, taking into account readability and concatenation capabilities.
4. Designed for token efficiency
Pagination, filtering, and truncation are enabled by default, and actionable improvement guidelines are given in the error message to avoid invalid retries and context waste.
5. Use "tool description" as a prompt project
The input and output should be unambiguous, and the examples should be close to the real business. Small adjustments to the description can significantly improve the success rate and completion of tool calls.
2. How to implement: prototype → evaluation → a closed loop of co-creation
1. Make a prototype first and then connect to MCP
Use Claude Code to draft the minimum available tools and documents, encapsulate the local MCP server or desktop extension, test the closed-loop self-test in the agent, and then access the API for programmatic experiments.
2. Systematic evaluation
Usereal data and complex tasks to generate evaluation sets, let agents run a complete tool call loop, and record time, number of calls, token consumption and error types, and assist decision-making with multi-dimensional indicators other than accuracy.
3. Collaborate with agents to optimize
Evaluate transcriptions and failure samples to Claude for analysis, and improve tool implementations and explanations in batches to prevent new changes from breaking consistency. Verify that the fit is not limited to the set set of the set of the Left Test.
3. Engineer's operation list
(1) Design
tools with a single purpose, clear input naming, verifiable output, and priority reuse of natural language identification.
(2) Performance
Limit the upper limit of the tool's response, giving priority to multiple accurate retrievals rather than one large package.
(3) Observable
Tool call logs, failure reasons and contextual summaries are kept for easy regression.
(4) Security
Distinguish between read-only and write-only tools, mark potentially destructive operations and set up manual access control.
Frequently Asked Questions (Q&A)
Q: How do I make AI agents use my tools more A
: Start with the tool description and give real-world scenario examples and parameter constraints; Use evaluation data to iteratively name and output structure, and provide detailed and concise returns when necessary, taking into account both readability and concatenation.
Q: What is the actual value of MCP for enterprise-level agents
A: MCP unifies multi-server and multi-tool access, facilitates namespace management and permission hierarchy, and allows agents to call hundreds of tools steadily without confusion.
Q: What should I do if the token cost is out of control
?A: Pagination and filtering at the tool layer, setting the upper limit of the number of response words, and optimizing the error copywriting; Guide the agent to replace one large search with multiple small searches.
Q: How to evaluate whether the tool has really become better
A: Establish a task set and set set that is close to the business, and record the accuracy, number of calls, time consumed, and tokens. Improved completion of real and complex tasks before and after the change.