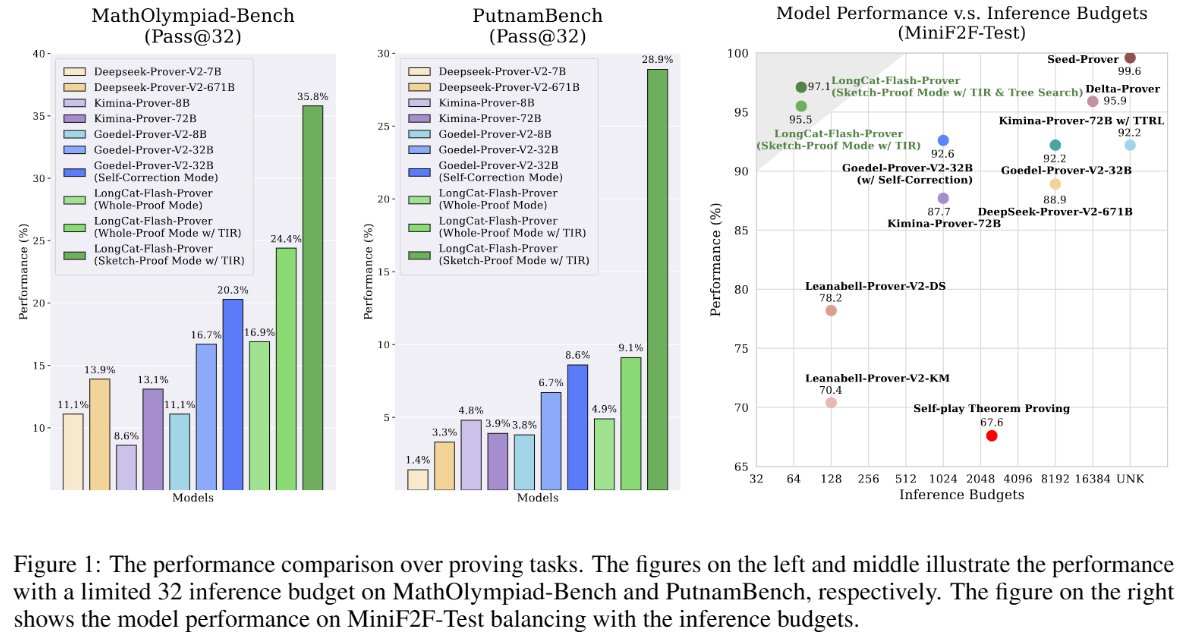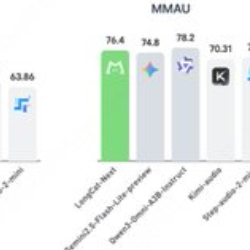
- Abstract
LongCat-Next is an open-sourced discrete native autoregressive multimodal model from Meituan's LongCat team, with the goal of unifying text, visuals, and audio in the same framework. The project adopts the MoE architecture, with a total parameter of about 68.5B and an activation parameter of about 3B, emphasizing the collaborative completion of "seeing, drawing, and speaking" in a single discrete token space, providing understanding, generation, and interaction capabilities for industrial-grade multimodal scenarios.
- Core features
- DiNA Paradigm: Extend Next-Token Prediction from language to native multimodality, unifying text, images, and audio into a shared discrete token space.
- dNaViT: Support discrete encoding and reconstruction of images of arbitrary resolution, taking into account both visual understanding and visual generation.
- Visual understanding: Covers tasks such as OCR, diagram understanding, GUI parsing, and document analysis, and has certain STEM reasoning skills.
- Visual generation: It supports arbitrary resolution generation under high compression ratio, which is highly competitive in text rendering scenarios.
- Voice capabilities: Support audio understanding, low-latency voice interaction, and customizable voice cloning.
- Installation
- Get the code from the official GitHub and create a running environment according to the repository instructions.
- Recommended environments include Python 3.10 and above, Torch 2.6 and above, Transformers 4.57.6 and above, and Accelerate 1.10.0 and above.
- After installing the requirements and supplementary dependencies, load the LongCat-Next weights from the Hugging Face.
- Official examples show that local inference based on Transformers usually requires at least 3 GPUs with 80GB of video memory.
- Typical use cases
- Document comprehension: identification and analysis of invoices, forms, reports, screenshots and other content.
- Interface analysis: Understand the software interface, button layout, and interaction process.
- Multimodal Q&A: Use text, images and audio as unified inputs for comprehensive reasoning.
- Image Generation: Generate posters, images with text, and multi-resolution visual content.
- Voice interaction: Realize voice question answering, speech-to-speech and customized speech synthesis.
- Ecology and competing products
- In terms of ecology, LongCat-Next has provided GitHub, Hugging Face, online demos, blog introductions, and technical report portals.
- Compared with the common "visual encoder or audio encoder plugged into LLM" scheme, LongCat-Next emphasizes native unified modeling.
- Compared with single-point optimal dedicated vision models, image generation models, or voice models, it has the advantage of unified framework and multi-task coverage, but at the cost of higher deployment complexity.
- Limitations and precautions
- The deployment threshold is high, and the requirements for video memory, bandwidth and overall computing power are obvious.
- Visual generation and voice cloning capabilities require additional consideration of security, copyright, and compliance issues in practical applications.
- Although the discrete visual route is characterized by the unity of understanding and generation, the specific effect should still be subject to the actual measurement of the target business.
- As a new open source project, its interfaces, dependencies, and best practices may continue to change.
- Project address
https://github.com/meituan-longcat/LongCat-Next
- Frequently asked questions
Q: What is LongCat-Next?
A: LongCat-Next is an open-sourced discrete, native autoregressive multimodal model from Meituan's LongCat team, which processes text, images, and audio in a unified manner.
Q: What is DiNA, the core technology of LongCat-Next?
A: DiNA is a modeling paradigm that extends Next-Token Prediction to native multimodality, unifying language, visuals, and audio with a shared discrete token space.
Q: What does LongCat-Next's dNaViT do?
A: dNaViT is a vision discretization and reconstruction module of LongCat-Next, which supports the understanding and generation of images of any resolution.
Q: What applications is LongCat-Next suitable for?
A: It is suitable for scenarios such as OCR, graph understanding, GUI parsing, document analysis, multimodal question answering, image generation, and voice interaction.
Q: Are there high hardware requirements for LongCat-Next on-premises deployments?
A: Yes, official examples show that its deployment has higher requirements for GPU video memory, making it more suitable for high-performance computing power environments.