1. Abstract
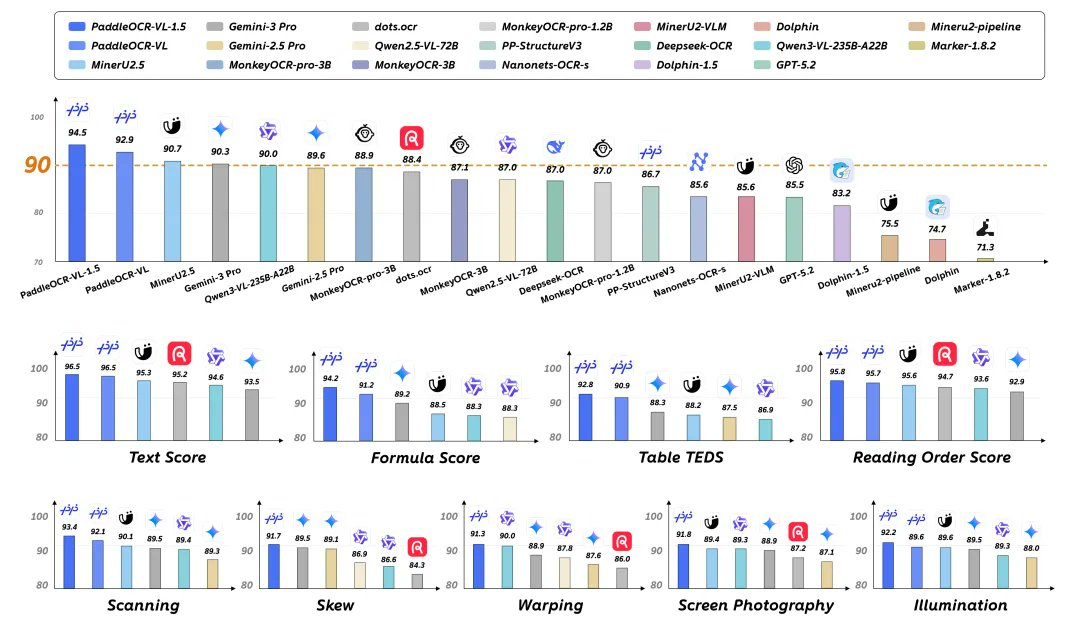
PaddleOCR-VL-1.5 is an open-source 0.9B parametric document multimodal model of PaddlePaddlePaddle, which provides integrated capabilities from layout positioning, reading order to structured analysis such as text/table/formula, etc., for real acquisition scenarios such as "bending, distorting, tilting, screen photography, and complex lighting". The official public results show that it achieves high accuracy on OmniDocBench v1.5 and Real5-OmniDocBench, which is suitable for document understanding and high-quality data extraction.
2. Core features
- Polygon/irregular area positioning: Multi-point polygons are used instead of rigid rectangular boxes, which better fit the boundaries of text and elements under curved and perspective distortion.
- Seal and signature recognition: Added the recognition capability for "seal/official seal" elements, which is suitable for the structured extraction of government and enterprise materials and compliance scenarios.
- Spread logic and global semantics: Support "whole document level" understanding such as spread table merging and title and hierarchical association, which is conducive to the semantic restoration of long documents.
- Multi-task parsing: Cover text, tables, formulas, charts, and other elements, and provide end-to-end document parsing output (such as Markdown/JSON).
- Lightweight and high throughput: 0.9B parameters are convenient for cost-controlled deployment; The official material gives end-to-end throughput data on the A100 for batch document processing.
- Multilingual: Official materials provide extensive multilingual coverage, including Tibetan, Bengali and other minor languages.
3. Installation
- Online experience: Directly use ModelScope Online Demo to upload images or PDFs to quickly verify the analysis effect of scenes such as bending and distortion, screen photography, etc.
- Local deployment: Clone the PaddleOCR repository, install dependencies and model resources according to official documentation, and prioritize using Docker to reduce environmental differences.
- Inference acceleration: When high throughput is required, use inference backends such as FastDeploy for service-oriented deployment and batch processing acceleration, combined with batch queue and concurrency parameter tuning.
4. Typical use cases
- Structure complex scans: Contracts, bills, papers, reports, etc., convert images/PDFs into usable structured Markdown/JSON.
- Spread table and table of contents restoration: Automatically merge and organize the spread table at the title level to improve the readability and retrievability of long documents.
- Seal element extraction: Extract the seal area and key information in the material verification and risk control archiving, and link it with the rules/manual review.
- Document RAG data pipeline: Preserve paragraphs, tables, page numbers, and element coordinates to improve retrieval recall, citation positioning, and answer traceability.
5. Ecology and competing products
- Ecology: PaddleOCR provides a complete toolchain from document rendering, layout analysis, to structured output, making it easy to implement batch processing and online services.
- Competing products: General multimodal large models and traditional OCR/document parsing solutions have their own advantages; PaddleOCR-VL-1.5 features overlay "True Distortion Document Resolution" multitasking with smaller parameters. The advantages and disadvantages of different schemes depend on the data distribution and evaluation settings, and it is recommended to use their own samples for regression testing before selection.
6. Limitations and precautions
- There is a risk of mistaken merger between span merging and hierarchical inference: For documents with extremely irregular layout and strong interference with headers and footers, rule verification and sampling review are required.
- Seal recognition has strong business attributes: the seal styles vary greatly between regions/units, and it is recommended to supplement domain data and threshold strategies.
- Throughput and cost depend on rendering and inference links: PDF rendering DPI, batch size, concurrency, and back-end implementation will significantly affect speed and cost.
- Publicity and comparison need to be interpreted carefully: If you see the comparison conclusion with some closed-source general models, you need to pay attention to the consistency of the evaluation set, prompt words and input processing.
7. Project address
https://github.com/PaddlePaddle/PaddleOCR
8. Frequently asked questions
Q: Is the PaddleOCR-VL-1.5 suitable for bending and twisting document OCR?
A: The official positioning is for scanning distortion, perspective distortion and screen cameras, and provides irregular area positioning and end-to-end resolution capabilities; It is recommended to use your real collection sample for verification.
Q: How do I build a high-precision document RAG with PaddleOCR-VL-1.5?
A: Prioritize outputting structured results (such as Markdown/JSON), retaining the title level, table structure, reading order, page number, and coordinates. Then click the "Paragraph/Table Block" to split into warehouses and create traceable references.
Q: What should I do if the spread table merging effect is unstable?
A: In the post-processing stage, add consistency checks (number of columns/header similarity/page number adjacency), and manually review or fall back to "parse per page" for low-confidence samples.
Q: What should I do if the throughput does not meet the official data?
A: Check PDF rendering time, input resolution, batch and concurrency, GPU utilization, and whether the officially recommended inference backend and parameters are used. Any link in the end-to-end link will become a bottleneck.
Q: Do you support Tibetan, Bengali, and other languages?
A: Official sources provide multilingual coverage and include Tibetan, Bengali, etc.; Before launching, it is still recommended to conduct special sampling and acceptance of the target language.