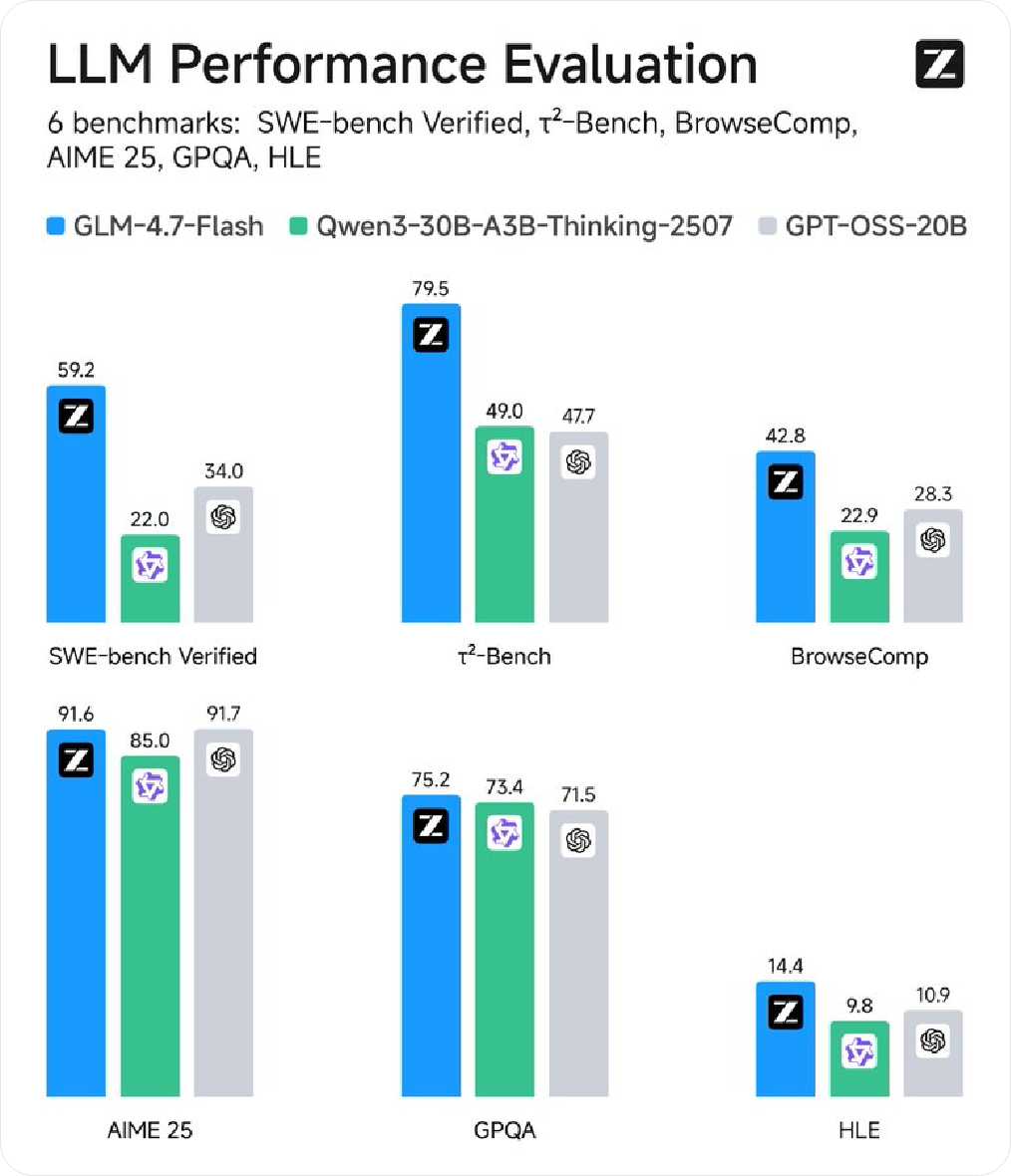
Z.ai related accounts posted information on X, introducing the new model GLM-4.7-Flash, positioned as a "local coding and agentic assistant", emphasizing that it balances high performance and efficiency at the 30B level, making it suitable as a lightweight deployment option. The synchronization information shows that model weights are already available in Hugging Face and support API calls via Z.ai.
The official developer documentation describes GLM-4.7-Flash as a free tier model with a "1 concurrency" limit; GLM-4.7-FlashX is also available as an optional version for "faster speed and more economical". In addition to programming, the public introduction also suggests that it be used in scenarios such as creative writing, translation, long-context tasks, and role-playing.
It should be noted that the actual threshold for "running locally" still depends on the deployment method and hardware resources; In addition, the free tier concurrency and commercial usage conditions should be based on the latest pricing and terms page of the platform to avoid misinterpreting the demo caliber as a universal usability commitment.
FAQs
Q: What is the core positioning of GLM-4.7-Flash?
A: GLM-4.7-Flash focuses on lightweight deployment, focusing on local coding assistance and agent workflows.
Q: Does GLM-4.7-Flash provide model weight downloads?
A: GLM-4.7-Flash weights are already available under Hugging Face's zai-org account.
Q: Is GLM-4.7-Flash's API free?
A: The Z.ai documentation labels GLM-4.7-Flash as a free tier, but the default limit is 1 concurrency.
Q: What is the difference between GLM-4.7-FlashX and GLM-4.7-Flash?
A: The public explanation says that GLM-4.7-FlashX is more high-speed and cost-effective, and is aimed at higher-frequency call scenarios.
Q: What non-programming uses is GLM-4.7-Flash suitable for?
A: The public introduction mentions that it can be used for creative writing, translation, long-context tasks, role-playing, etc.