1. Abstract
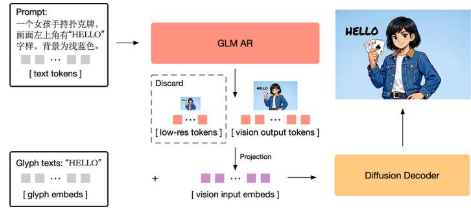
GLM-Image is an open-source image generation model from Z.ai, using a hybrid paradigm of "discrete autoregressive generation + diffusion decoding": the autoregressive module is responsible for global semantics and layout planning, and the diffusion decoder is supplemented with high-fidelity details. Official information points out that its overall image quality can align with the mainstream diffusion route, and at the same time, it performs more prominently in text rendering and knowledge-intensive images (posters, PPTs, popular science diagrams).
2. Core features
- Hybrid architecture: take into account instruction understanding (global) and detail restoration (local).
- More stable text: more suitable for multi-line text, heading/subheading hierarchy and information card layout.
- Knowledge-intensive generation: Pictures for "information expression first", such as flowchart posters and annotation diagrams.
- Wensheng Diagram + Tushengtu: Support generating, editing, and style/consistency-related tasks (subject to official examples).
3. Installation
- Get code and weight: GitHub clone repository; Download the model weights from Hugging Face.
- Python inference: Install dependencies such as Transformers/Diffusers according to the repository instructions, load the pipeline for generation.
- Interface call: You can directly use the images/generations endpoint of the Z.ai API to pass in parameters such as prompt and size.
4. Typical use cases
- Posters and event materials: Promotional graphics with "clear and readable text + stable layout" are required.
- PPT information page: chapter covers, key points, comparison charts and other information-dense screens.
- Popular science diagram and annotation diagram: emphasize semantic correctness and information structure, rather than pure stylized art.
- Brand consistency output: Multiple images keep the style consistent with the main body and reduce rework.
5. Ecology and competing products
- Ecology: Hugging Face provides models and instructions; Official documentation provides APIs and parameters; GitHub provides native inference and examples.
- Competing products: Compared with mainstream routes such as SDXL/SD3 and FLUX, GLM-Image is more inclined to the "text + knowledge expression" scenario; Universal style coverage and cost recommendations use your prompts to compare and evaluate the data.
6. Limitations and precautions
- Computing power threshold: Hybrid architecture and high-resolution generation may require higher video memory/multi-card support.
- Dimensional constraints: It is common to require the width and height to be a specific multiple (such as a multiple of 32), otherwise an error may be reported.
- Text still needs to be accepted: manual review is recommended for small font sizes, complex fonts, and multilingual mixed layout scenarios.
7. Project address
https://github.com/zai-org/GLM-Image
8. Frequently asked questions
Q: What are the benefits of GLM-Image's "autoregression + diffusion decoding" hybrid architecture?
A: Self-regression is better at global semantics and layout planning, diffusion is better at detail and texture completion, and it is more conducive to information-dense image generation after combination.
Q: Why is GLM-Image more advantageous in rendering images in Chinese?
A: The official materials emphasize that it has been specially designed and trained for text and information expression, making the generated text clearer and closer to the expected layout.
Q: What knowledge-intensive scenarios is GLM-Image suitable for?
A: Posters, PPT information pages, popular science diagrams, pictures with multi-region annotation and hierarchical information.
Q: Can GLM-Image do image generation/editing?
A: Yes, the repository and model pages provide relevant usage and example parameters (subject to the official one).
Q: What should I do if GLM-Image can't run locally?
A: Reduce the resolution and number of steps first, use larger memory/multiple cards if necessary, or use the Z.ai API instead.
Q: Why does the GLM-Image generated size error?
A: The common reason is that the width and height do not meet the multiple constraints required by the model; Adjust to compliant dimensions according to the document.