1. Abstract
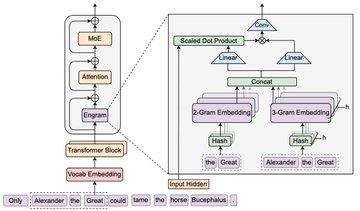
Engram is an open-source "Conditional Memory" module from DeepSeek, and the core idea is to add an extensible form-lookup memory primitive to the Transformer: a part of the more static pattern/knowledge is stored in the form of an N-gram memory table, retrieved in an approximate O(1) manner during inference, and fused with the current hidden state. The conclusion given by the official repository is that under the constraints of equal parameters and equal computing power, Engram-27B has stable returns compared to the MoE baseline in tasks such as knowledge, reasoning, code, and mathematics. And the mechanism analysis shows that it can reduce the burden of "reconstruction" of the static model in the early layer, so as to leave the effective depth for more complex inference calculations.
2. Core features
1. O(1) Form form condition memory
By deterministic addressing and retrieval of static N-gram memory, the "knowledge search" is partially separated from dense neural computing, reducing the occupation of the computational path.
2. "Sparse new axis" complementary to MoE
MoE expands capacity through conditional calculation, and Engram expands capacity through conditional memory: one is "calculated" and the other is "checked", which can be more effectively allocated model capabilities under the same FLOPs after combination.
3. The U-shaped scale law is used for capacity allocation
The official trade-off between "Computational Capacity (MoE) and Static Memory Capacity (Engram)" is given, and points out that there is a U-shaped scaling law that can guide engineering trade-offs.
4. The mechanism explanation is closer to the engineering intuition
The repository explicitly mentions that Engram may eliminate the need for early layers to repeatedly reconstruct static patterns, leaving the number of layers and representation capabilities to subsequent more critical inference processes, which can be understood as "more effective deepening for inference".
5. System efficiency and landability
Deterministic addressing is used to offload hyperscale embedded tables to host memory, and the increment of inference overhead is kept as controllable as possible.
3. Installation
1. Prepare the environment
Python 3.8+, an isolated environment (venv/conda) is recommended.
2. Installation dependencies
Quick Start by repository: Install dependencies such as torch, numpy, transformers, sympy, etc.
3. Run the demonstration
The repository provides engram_demo_v1.py for demonstrating Engram's core data flows; This version will mock some standard components (e.g. Attention/MoE, etc.) and highlight how Engram modules work.
4. Typical use cases
1. Knowledge-intensive Q&A and factual recall
When the task relies more on "stable knowledge/fixed expression mode", lookup memory can reduce the repetitive pattern reconstruction of the model in the first few layers.
2. Stable fragment reuse in long context
Static memory hits for recurring short fragments (fixed phrases, code templates, common formats) to reduce invalid calculations in long contexts.
3. Templated structure of code and mathematical scenarios
In tasks with more "common derivation routines/code skeletons", memory channels are used to undertake more static structures, and computational channels focus on combination and reasoning.
4. Cost-effective expansion combined with MoE
Under the premise that the total parameters and total FLOPs are limited, the "part of the capacity is put into the static memory table" in exchange for a higher effective capacity density.
5. Ecology and competing products
1. Ecological status
Currently, the official repository is mainly based on papers + structure diagrams + experimental diagrams + demos, which is suitable for quickly understanding the new component of "conditional memory" and evaluating the combination space with the existing MoE stack.
2. Competing products and adjacent directions
Neighboring ideas typically include: RAG (External Retrieval Enhancement), kNN-LM/Nearest Neighbor Retrieval, Traditional N-gram/Caching, and various sparse attention/sparse routing architectures. The difference of Engram is that it uses "trainable static memory table" as the internal primitive of the model, and emphasizes the division of labor and scaling with MoE. The actual effect still needs to be verified in combination with specific data distribution, training recipe, and deployment constraints.
6. Limitations and precautions
1. Details and reproduction caliber of the paper
The repository provides key conclusions and demos, but the details of large-scale training, addressing implementation, and complete ablation should still be based on the paper.
2. Memory and deployment trade-offs
Offloading huge memory tables to host memory reduces memory pressure, but introduces new constraints on bandwidth, latency, and engineering complexity.
3. Applicability depends on the form of the task
If the main bottleneck of the task is "dynamic reasoning/combinatorial generalization" rather than "static mode/knowledge reuse", the benefits may not be as obvious as knowledge-intensive tasks.
4. Integration cost with existing training system
To connect new modules to existing MoE/attention implementation and parallel strategies, you need to evaluate training stability, throughput, and monitoring metrics (such as hit rate, table capacity utilization, etc.).
7. Project address
https://github.com/deepseek-ai/Engram
8. Frequently asked questions
Q: What are the core keywords of Engram and what problems does it solve?
A: The keywords are Conditional Memory, Scalable Lookup, O(1) lookup memory, and N-gram memory. It tries to give the transformer the ability to "native knowledge lookup" to separate some of the static patterns/knowledge from intensive computation.
Q: What is the relationship between Engram and MoE?
A: MoE expands capacity through conditional calculation, and Engram expands capacity through conditional memory. The two can complement each other to form a division of labor of "calculation (calculation) + check (memory)".
Q: What does the official mechanistic analysis mean by "more effective and deeper"?
A: The repository view is that Engram reduces the burden of rebuilding static patterns at the early layers, making network depth more focused on subsequent complex inference, which is like "leaving depth for key parts".
Q: How can I quickly verify how Engram works?
A: To directly run the engram_demo_v1.py provided by the warehouse, first understand the data flow and fusion location. The demo will mock common components to highlight Engram.
Q: Is Engram suitable as an alternative to RAG?
A: It is more suitable as a supplementary direction: RAG is external document retrieval and update, and Engram is internal static memory primitive language and computing/memory division of labor. The substitution depends on whether the task requires external updatable knowledge and a controllable retrieval link.



