1. Leistungsabschluss
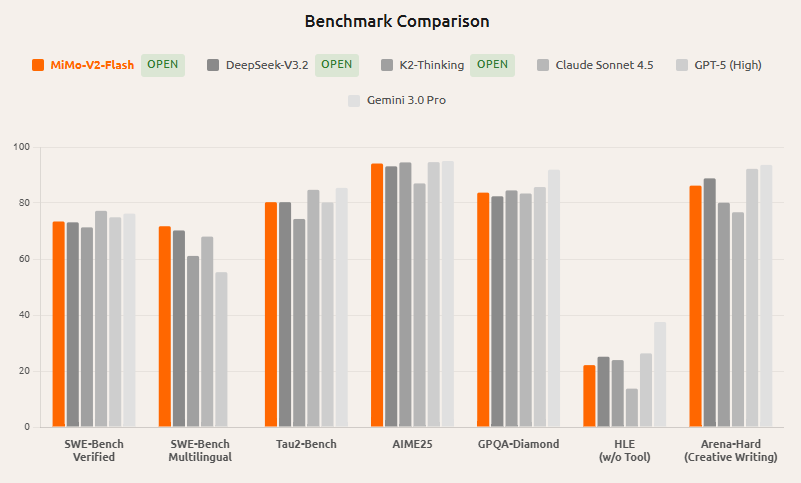
In der Xiaomi MiMo-Serie verfolgt MiMo-V2-Flash den Weg der "Hocheffizienzdichte": 309 Milliarden Gesamtparameter der MoE-Architektur und etwa 15 B Aktivierungsparameter. Seine Modellkarten zeigen eine starke Leistung bei einer Reihe von allgemeinen und Inferenz-Benchmarks, wobei insbesondere Code- und Agentenbewertungen hervorgehoben sind.
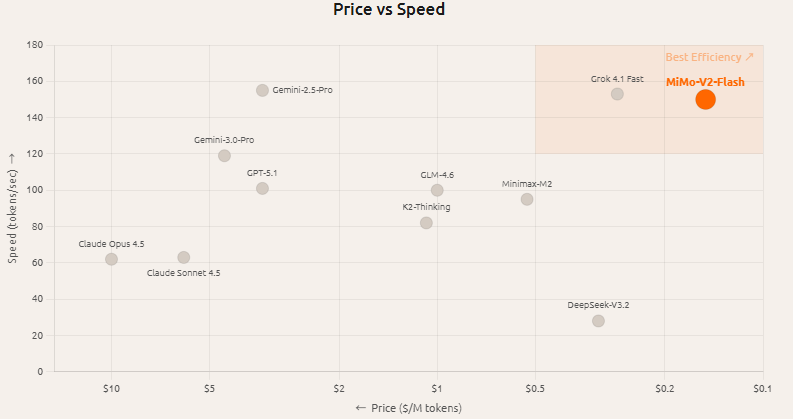
2. Geschwindigkeit und Kosten Laut
offizieller Einführung verwendet es hybride Aufmerksamkeit, Multi-Token-Vorhersage und andere Designs, um den Inferenzaufwand zu reduzieren, und bietet 256.000 lange Kontexte, was eher für Multiround-Toolaufrufe und Workflow-Szenarien ausgerichtet ist.
3. Wie man Benchmarking betrachtet
: Viele Interpretationen von Drittanbietern vergleichen es mit High-End-Open-Source-Modellen wie DeepSeek-V3.2; Allerdings unterscheiden sich die Fragebank mit verschiedenen Listen, ob Werkzeuge verwendet werden, und die Argumentationseinstellungen sehr unterschiedlich, und die Werte sollten nicht direkt ausgeglichen werden; es wird empfohlen, die Ergebnisse unter denselben Bedingungen wiederzugeben.
4. Landungsvorschläge
Beurteilen, ob es "für Sie geeignet" ist, und verwenden Sie Ihr eigenes Aufgabenset für offline A/B: Achten Sie auf Durchsatz und Latenz, Halluzinationsrate, Tool-Erfolgsrate und Stückkosten; Vor Ort Neubewertung von Quantifizierung, Parallelität und Framework-Passung.
5. Fragen und Antworten Häufig gestellte Fragen F
: Ist 309B schwer zu leiten?
A: Die Inferenz wird hauptsächlich bei etwa 15 B aktiviert, aber eine starke GPU/Multi-Karte wird weiterhin empfohlen; Quantifizierung senkt die Einstiegshürde erheblich.
F: Ist es besser, Code zu schreiben oder zu chatten?
A: Die Positionierung ist stärker auf Inferenz, Codierung und Agenten-Workflows ausgerichtet; Der reine Chatstil und die Stabilität sollten von deiner tatsächlichen Messung der Szene abhängen.
F: Gibt es kleinere MiMos?
A: Ja, MiMo hat auch das 7B-Inferenzorientierte Modell veröffentlicht, das sich für leichte Forschung und Vergleich eignet.