Xiaomi MiMo und das Xiaomi Large Model Core Team haben MiMo-V2-Flash-bezogene Ressourcen veröffentlicht und geöffnet, positioniert es als grundlegendes Sprachmodell für Hochgeschwindigkeits-Schlussfolgerungen und Agenten-Workflows, und die Modellgewicht- und Inferenz-Implementierungsdaten werden gleichzeitig Entwicklern und Forschern zur Verfügung gestellt.
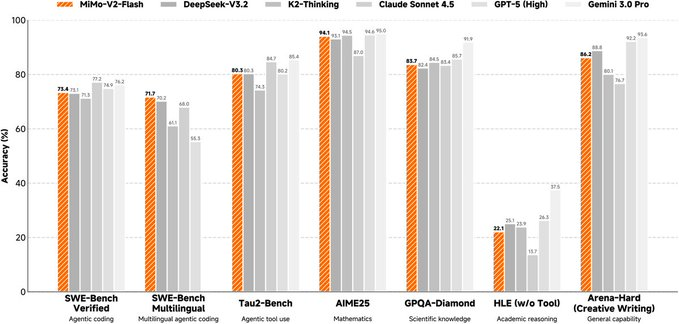
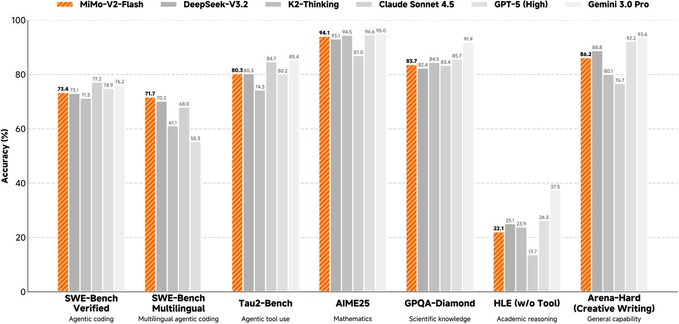
Das Modell ist eine Mix-of-Experts-(MoE)-Architektur mit einem Gesamtparameter von etwa 309B, einer Aktivierung von etwa 15B während der Inferenz und unterstützt eine maximale Kontextlänge von etwa 256K. Das Design mit gemischter Aufmerksamkeit verbindet gleitende Fensteraufmerksamkeit proportional mit globaler Aufmerksamkeit und verwendet ein kleineres Fenster, um den KV-Cache-Overhead zu komprimieren. Gleichzeitig wird ein leichtes Multi-Token-Vorhersagemodul (MTP) eingeführt, um die Ausgabegeschwindigkeit der Dekodierung zu verbessern, und der offizielle Dienst stellt zusätzlich mehrschichtige MTP-Gewichte für die Gemeinschaftsforschung bereit. Die Modellseite und das Repository bieten Trainings- und Nachtrainingspunkte (einschließlich FP8-Mixed-Precision- und agentenorientierter Reinforcement Learning/Destillationsrouten) und listen mehrere Evaluationsergebnisse zum Vergleich auf.
Es sollte beachtet werden, dass solche ultragroß angelegten MoE-Modelle hohe Anforderungen an Rechenleistung und Inferenzrahmen stellen und die Bewertungsergebnisse sowie tatsächliche Geschäftseffekte durch Prompts, Werkzeugketten sowie parallele Quantifizierungs- und Inferenzstrategien beeinflusst werden können. Vor der kommerziellen Nutzung und Weiterverbreitung sollten Sie auch die spezifischen Lizenzbedingungen und den Umfang der Modellseite und des Code-Repositorys prüfen.
FAQ
F: Was für ein Modell ist MiMo-V2-Flash?
A: MiMo-V2-Flash ist ein MoE-Grundsprachmodell, das vom Xiaomi MiMo-Team veröffentlicht wurde und auf Hochgeschwindigkeits-Inferenz- und Agentenaufgabenszenarien abzielt.
F: Wie hoch ist die Parametergröße und die Kontextlänge von MiMo-V2-Flash?
A: Öffentliche Informationen zeigen, dass die Gesamtparameter etwa 309B betragen, die Aktivierung etwa 15B beträgt und sie eine maximale Kontextlänge von etwa 256K unterstützt.
F: Welche Probleme löst der MiMo-V2-Flash hauptsächlich mit "gemischter Aufmerksamkeit" und MTP?
A: Die gemischte Aufmerksamkeit konzentriert sich darauf, die KV-Caching-Kosten der Langkontextinferenz zu senken, während MTP sich auf die Verbesserung des Ausgangsdurchsatzes und der Geschwindigkeit in der Dekodierungsphase konzentriert.
F: Wo kann ich die Modellgewichte und technischen Berichte für MiMo-V2-Flash bekommen?
A: Modellgewichte sind auf Hugging Face verfügbar, Code und technische Berichte sind im GitHub-Repository verfügbar, und der offizielle Website-Blog sowie LMSYS-Artikel sind ebenfalls organisiert.
F: Was ist die häufigste Grube, auf die MiMo-V2-Flash beim Einsatz getreten ist?
A: Häufige Probleme sind unzureichender Speicher/Bandbreite, unvollständige Unterstützung für Inferenzrahmen für MoE und MTP sowie unsachgemäße Quantisierung und parallele Konfiguration, die zu Geschwindigkeits- oder Qualitätsschwankungen führen.