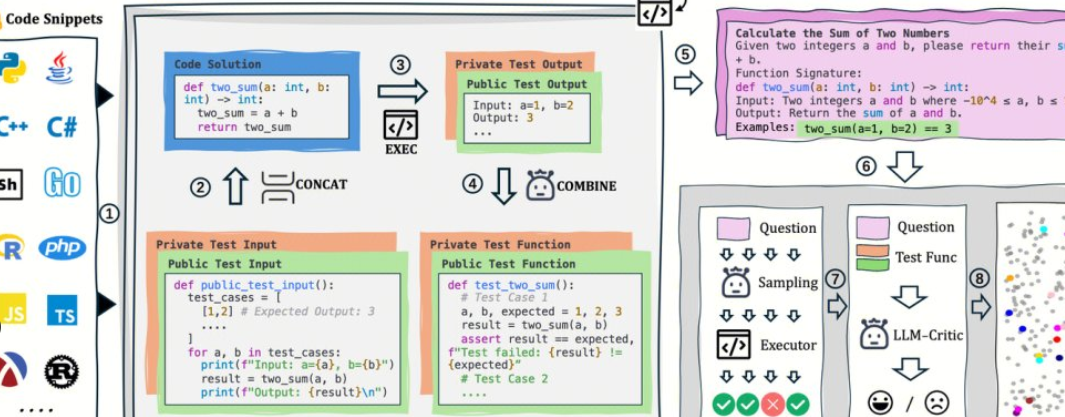
AutoCodeBench wird vom Hunyuan-Team von Tencent als Open Source bereitgestellt, und sein Kern ist ein automatisierter Workflow von "LLM-Generierung + mehrsprachige Sandbox-Validierung". Das Projekt stellt auch AutoCodeGen (Datensynthese), AutoCodeBench (drei Sätze von Benchmarks, Full / Lite / Complete) und MultiLanguageSandbox (30+ Sprach-Sandboxen) zur Verfügung, um die mehrsprachigen Codierungsfähigkeiten von Base- und Chat-Modellen zu bewerten und die Selbstgenerierung neuer Benchmarks zu unterstützen.
1. Projektübersicht und Wert
- Keine manuelle Annotation: LLM wird verwendet, um Fragen und Referenzantworten zu synthetisieren, und überprüfbare Standardausgaben werden automatisch über die Sandbox generiert.
- Mehrsprachig und schwierig: Mit 20 Programmiersprachen und 3.920 praktischen Problemen ist die Schwierigkeitsschichtung näher an der realen Entwicklung.
- Auswertung und Daten sind die gleiche Quelle: Derselbe Prozess kann nicht nur Daten generieren, sondern auch die Auswertung wiedergeben, was für die Reproduzierbarkeit und den horizontalen Vergleich praktisch ist.
2. Open-Source-Adresse
1. Projekt-Homepage: https://autocodebench.github.io
2. Papier: https://arxiv.org/abs/2508.09101
3. Codebasis: https://github.com/Tencent-Hunyuan/AutoCodeBenchmark
3. Daten- und Benchmark-Komposition
- Vollständig: 3.920 Fragen in 20 Sprachen, wobei Schwierigkeit und Vielfalt im Vordergrund stehen.
- Lite: 1.586 Fragen, gescreent nach modellübergreifender "Lösbarkeit", was für einen schnellen Vergleich förderlicher ist.
- Abgeschlossen: 1.000 Fragen, 3-Schuss-Einstellung, Bewertung der Code-Vervollständigung für das Basismodell.
- Sprache und Schwierigkeit: Ausgewogene Stichprobenerstellung je nach Sprache, der Schwierigkeitsgrad wird unter Berücksichtigung sowohl der Breite als auch der Intensität in leicht/mittel/schwer unterteilt.
4. Bewertungsparadigma und Indikatoren
- Einheitliche Anweisungen: Erfordern die Ausgabe eines einzigen Codeblocks, ohne dass Befehle und Beispiele ausgeführt werden müssen.
- Sandbox-Verifizierung: Kompilieren/Ausführen des generierten Codes Thema für Thema, Berechnen objektiver Indikatoren wie pass@1.
- Zweizeilige Bewertung: Deckt gleichzeitig die Chat-Generierung und die Base-Vervollständigung ab, um die Verzerrung zu reduzieren, "nur das Dialogmodell zu testen".
5. Schneller Einstieg (5 Schritte)
1. Bereiten Sie die Ausgabe vor: Verwenden Sie Ihr Modell, um Fragen für Fragen in autocodebench.jsonl Frage für Frage zu generieren und als model_output.jsonl zu speichern.
2. Ziehen Sie das Image: docker pull hunyuansandbox/multi-language-sandbox:v1.
3. Starten Sie den Dienst: docker run -d --name sandbox -p 8080:8080 hunyuansandbox/multi-language-sandbox:v1.
4. Gesundheitsprüfung: Senden Sie die Mindestprobe an POST /submit, um zu bestätigen, dass die Kompilierung/Ausführung normal ist.
- Berechnungsmetriken: Verwenden Sie Warehouse-Skripte, um Sandboxes in Batches aufzurufen, Ausführungsergebnisse zu generieren und pass@1 zu zählen.
6. Typische Anwendungen und anwendbare Gruppen
- Modellteam: sprachübergreifende Regression und Versionsvergleich, Lokalisierung von Kompilierungsfehlern/Grenzanwendungsfällen.
- Bewertung wissenschaftlicher Forschung: Erstellen Sie qualitativ hochwertige mehrsprachige Benchmarks zu geringen Kosten, um die Reproduzierbarkeit zu verbessern.
- Interne Tests im Unternehmen: Verwenden Sie Lite/Complete, um Graustufenbewertungen durchzuführen, die Stabilität zu beobachten und Long-Tail-Fragen zu stellen.
7. Praktische Vorschläge
- Zuerst Lite und dann Full: Führen Sie zuerst schnell ein Screening durch und führen Sie dann eine umfassende Regression und einen Bericht durch.
- Parallelität und Quoten: Die Kompilierung/Ausführung von Sandbox ist ein Engpass, und es wird empfohlen, Warteschlangen zu planen und sie verteilt zu implementieren.
- Beobachtbarkeit: Fehler des Datensatzes nach Typ (Kompilierung/Lauf/Grenze/Zeitlimit), gezielten Optimierungsaufforderungen und Hyperparametern.
- Zusammenarbeit mit der RAG: Lange Fragen und dateiübergreifende Aufgaben werden mit Verbesserungen bei der Suche kombiniert, um die Stabilität zu erhöhen.
8. Einschränkungen und Risikowarnungen
- Konsistenz der Umgebung: Spiegelung und Abhängigkeiten wirken sich auf die Erfolgsrate aus, und es ist notwendig, die Version und zufällige Startwerte zu sperren.
- Datenkonformität: Wenn das Thema und der Code externe Datenbanken betreffen, ist es notwendig, eine gute Isolation und Überwachung durchzuführen.
- Extrapolierte Grenze: Die Benchmark-Punktzahl ist nicht gleich der Produktionsverfügbarkeit, und es ist immer noch eine echte Geschäftsstichprobe A/B erforderlich.
9. Häufig gestellte Fragen
- Ist es wirklich "vollautomatisch und ohne manuelle Annotation"?
Der Prozess konzentriert sich auf die LLM-Generierung und die Sandbox-Verifizierung und verlässt sich nicht auf manuelle Annotationen von Thema zu Thema. Zur Überprüfung der Qualität wird eine manuelle Probenahme von Schlüsselproben empfohlen.
- Welche Sprachen werden unterstützt und ist es in Richtung Python ausgerichtet?
Die Sandbox unterstützt 30+ Sprachen und deckt 20 Programmiersprachen mit Datenausgleich ab, wodurch die "Python only"-Tendenz erheblich reduziert wird.
- Wie kann man Chat und Base gleichzeitig bewerten?
Chat generiert Code direkt aus Eingabeaufforderungen des einheitlichen Systems. Base verwendet die 3-Shot-Abschlusseinstellungen von Complete, um das Evaluierungsprotokoll konsistent zu halten.
- Kann ich denselben Workflow verwenden, um benutzerdefinierte Baselines zu generieren?
Okay. AutoCodeGen synthetisiert automatisch neue Fragen und Testsätze in einer Sandbox mit dem gleichen Überprüfungs- und Bewertungsprozess.



