1. Abstract
LongCat-Image ist ein Open-Source-Modell zur bilingualen Bilderzeugung und -bearbeitung auf Chinesisch und Englisch von Meituans LongCat-Team mit Parametern von etwa 6 B, das eine hybride DiT-Architektur verwendet, die mit einigen Open-Source-Modellen auf 20B-Niveau in vielen öffentlichen Benchmarks vergleichbar ist oder sogar übertrifft. Das Projekt konzentriert sich darauf, die mehrsprachige Textwiedergabe, Bildkonsistenz und realistische Effekte zu verbessern und berücksichtigt die Inferenzgeschwindigkeit und die Nutzung des Videospeichers, wodurch es für Forschung und Geschäftsumsetzung geeignet ist.
2. Kernmerkmale
- Zweisprachige Textfähigkeit in Chinesisch und Englisch: Spezielle Optimierung für komplexe chinesische chinesische Zeichen (einschließlich seltener Zeichen) und herausragende Leistung bei chinesischen Textrenderingindikatoren.
- Vereinheitlichte Generierung und Bearbeitung: Bereitstellung von LongCat-Image, LongCat-Image-Dev, LongCat-Image-Edit und weiteren Versionen, die Aufgaben wie Textbilder, Ganz-/Teilbearbeitung und Textmodifikation abdecken.
- Leichte und effiziente Inferenz: Die 6B-hybride DiT-Architektur unterstützt Inferenz mit geringer Präzision und balanciert Geschwindigkeit und Qualität auf begrenztem Videospeicher.
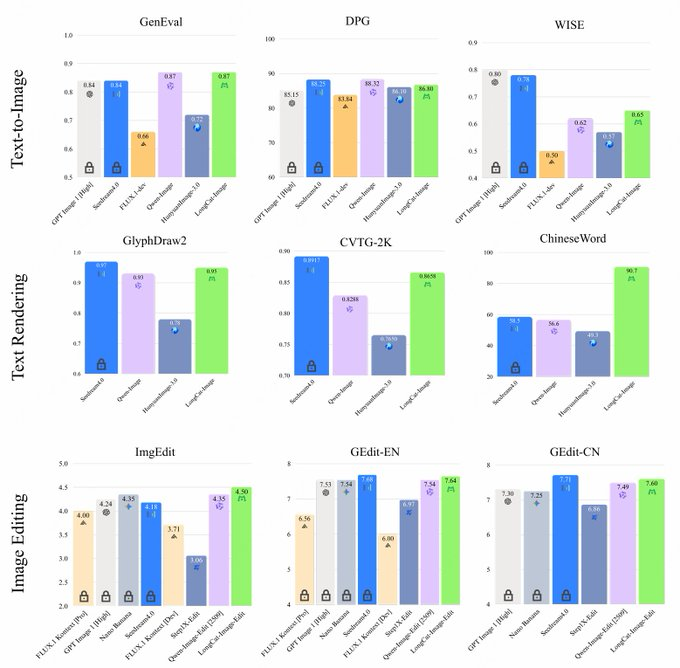
- Realismus und Ausrichtung: In Kombination mit Datenstrategie und RL-Training verbessert es die Ausrichtung von Objektstruktur, Stil und Anweisungen und befindet sich auf derselben Ebene wie das Kopfmodell bei Benchmarks wie GenEval und DPG.
- Vollständige Toolchain: Bietet Trainingscode, Beispiele und zwischenbestehende Checkpoints unter der Open-Source-Lizenz, was die Fortsetzung von Training, LoRA und DPO-Forschung erleichtert.
3. Installation
- Umgebungsvorbereitung: Es wird empfohlen, Python 3.10 und NVIDIA GPUs zu verwenden, die CUDA unterstützen, und es ist sicherer, Videospeicher von 16–24 GB zu verwenden.
- Klon-Repository
git clone --single-branch --branch main https://github.com/meituan-longcat/LongCat-Image
cd LongCat-Image
- Installationsabhängigkeiten:
conda create -n longcat-image python=3.10
conda activate longcat-image
pip install -r requirements.txt
__CODE_ INLINE_5__
- Gewichte herunterladen:
Verwenden Sie huggingface-cli, um die LongCat-Image / LongCat-Image-Dev / LongCat-Image-Edit Gewichte aus dem entsprechenden Repository in das lokale Verzeichnis zu laden und auf den Pfad in der Konfiguration zu zeigen.
4. Typische Anwendungsfälle
- Chinesische/englische Textgrafiken: Plakate, E-Commerce-Karten, Operationsmaterialien usw., die hohe Anforderungen an chinesische Glyphen, Typografie und Themenkonsistenz verlangen.
- Bildbearbeitung in natürlicher Sprache: globale Stilersetzung, teilweise Modifikation, Objekthinzufügen und -löschen, Textinhaltsersatz usw. je nach Text.
- Visuelle Anpassung der Marke: LoRA kombinieren oder weitertrainieren, um Markencharaktere, Farbabstimmung und Kompositionsstile für langfristige einheitliche Ergebnisse zu festigen.
- Akademische und ingenieurtechnische Grundlage: Als Open-Source-Basis für zweisprachige Bildmodelle auf Chinesisch und Englisch validieren Sie neue Verluste, neue Datenverhältnisse oder neue RL-Strategien.
5. Ökologie und konkurrierende Produkte
- Ökologie: Offiziell Trainingspipelines, Inferenzskripte bereitstellen und schrittweise mit Diffusoren, ComfyUI und anderen Ökosystemen integrieren, um den Zugang zu bestehenden AIGC-Prozessen zu erleichtern.
- Vergleich der Konkurrenten: Im Vergleich zu Modellen wie Qwen-Image, HunyuanImage, Seedream und FLUX hat LongCat-Image offensichtliche Vorteile bei chinesischen Textrendering- und Bearbeitungsbenchmarks, mit kleineren Parametern und niedrigeren Deployment-Schwellen. Der spezifische Effekt muss weiterhin mit Geschäftsdaten und subjektiver Bewertung kombiniert werden.
6. Einschränkungen und Vorsichtsmaßnahmen
- Rechenleistungsanforderungen: Hochauflösende Generierung und mehrstufiges Schneiden erfordern weiterhin viel Videospeicher, und kleine Videospeichergeräte müssen Auflösung, Anzahl der Schritte oder Batch-Größe reduzieren.
- Sprach- und Szenenumfang: Hauptsächlich für Chinesisch und Englisch optimiert, andere Sprachen oder extreme visuelle Szenen können instabil sein.
- Inhaltskonformität: Das Modell kann unangemessene Inhalte erzeugen, und die eigentliche Implementierung muss mit Sicherheitsaudits, Keyword-Filterung und manueller Überprüfung kooperieren.
- Unsicherheit außerhalb des Benchmarks: Öffentliche Benchmark-Ergebnisse spiegeln die Leistung von Geschäftsszenarien nicht vollständig wider, daher wird empfohlen, A/B-Tests und manuelle Qualitätskontrollen durchzuführen.
7. Projektadresse
https://github.com/meituan-longcat/LongCat-Image
8. FAQs
F: Welche Kernaufgaben unterstützt LongCat-Image?
A: Es unterstützt zweisprachige Text-zu-Bild-Generierung, vollständige oder teilweise Bildbearbeitung, Textinhaltsänderung, Referenzbild-Constraint-Bearbeitung usw., und verschiedene Versionen legen ihren eigenen Schwerpunkt auf Generierung, Entwicklung, Debugging und Bearbeitung.
F: Wie viel Videospeicher benötigt LongCat-Image-Inferenz?
A: Der offizielle Satz gibt keine feste Untergrenze an, und die allgemeine Erfahrung ist, dass eine einzelne Karte normale Auflösungsaufgaben mit 16–24 GB Videospeicher ausführen kann; Für hohe Auflösung oder Batch-Erstellung kannst du mehrere Karten verwenden oder die Auflösung sowie die Anzahl der Schritte reduzieren.
F: Was sind die Vorteile von LongCat-Image bei der chinesischen Textgenerierung?
A: Es übertrifft viele Open-Source-Modelle bei Benchmark-Indikatoren wie der Genauigkeit chinesischer Zeichen, komplexer Glyphenwiederherstellung sowie Bild- und Textkonsistenz, wobei die Gesamtbildqualität und Lesbarkeit berücksichtigt werden.
F: Ist LongCat-Image einfach weiterzuführen oder LoRA-Feinabstimmung?
A: Ja. Das Projekt verfügt über eine offene Trainings-Toolchain und einen Zwischenkontrollpunkt, der für SFT-, LoRA-, DPO- und Bearbeitungsschulungen genutzt werden kann, jedoch die Vorbereitung entsprechender Rechenleistung und hochwertiger Datensätze erfordert.