1. Abstract
Mistral 3 ist eine neue Generation von Open-Source-Modellfamilien, die von Mistral AI gestartet wurde, darunter Mistral Large 3 mit spärlicher Expertenarchitektur und die Ministral 3-Serie (3B/8B/14B) für lokale und Randszenarien. Alle Gewichte sind unter der Apache 2.0-Lizenz offen, unterstützen Multimodal (Text + Bild) und mehrsprachig und decken unterschiedliche Rechenleistungs- und Kostenanforderungen von einzelnen Entwicklern bis hin zu unternehmensweiten Inferenzen ab.
2. Kernmerkmale
- Multimodellfamilien: Large 3 (MoE-Architektur, 41B aktive Parameter, 675B Gesamtparameter) und Ministral 3 (3B/8B/14B, einschließlich Basis-/Instruktions-/Schlussfolgerungsvarianten).
- Open Source und Kommerzialisierung: Die Apache 2.0-Lizenz wird einheitlich übernommen, was sich für die Entwicklung und Privatisierung von Unternehmenssekundären eignet.
- Multimodal und mehrsprachig: Unterstützt das Bildverständnis und den Dialog in 40+ Sprachen und ist in nicht-englischsprachigen Szenarien gut geeignet.
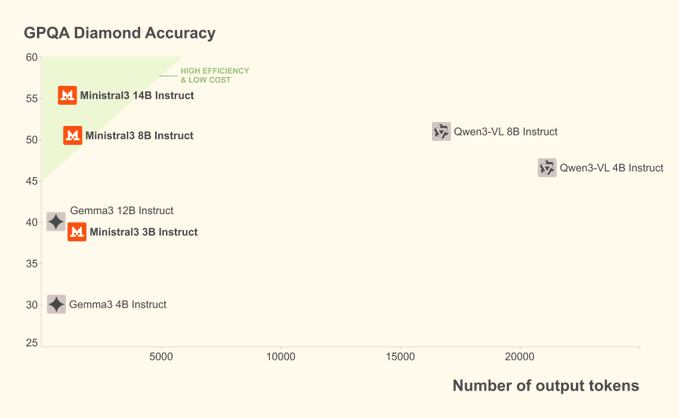
- Kosteneffiziente Optimierung: Die Ministral-Serie betont "weniger Token, ähnliche oder bessere Ergebnisse", um die Inferenzkosten zu senken.
- Hardware-Kollaborationsoptimierung: Zusammenarbeit mit NVIDIA, vLLM, Red Hat usw., um sich an Inferenzlösungen mit geringer Präzision wie Hopper/Blackwell-GPUs, TensorRT-LLM, SGLang usw. anzupassen.
3. Installation
- Cloud API: Eröffnen Sie ein Konto bei Mistral AI Studio, Amazon Bedrock, Azure Foundry und anderen Plattformen und rufen Sie Mistral 3-Serien-Modelle über das offizielle SDK oder HTTP-API auf.
- Open-Source-Gewichte: Laden Sie Large 3- und Ministral-3-Gewichte von Hugging Face und anderen Kanälen herunter und setzen Sie sie in Kombination mit vLLM, TensorRT-LLM, SGLang und anderen Inferenz-Frameworks ein.
- Lokal/Edge: Wähle je nach Modellgröße eine einzelne Multi-Card oder eine lokale GPU/High-End-Grafikkarte für Verbraucher; Das Ministral 3B/8B eignet sich besser für Laptops, Edge-Geräte und Embedded-Implementierungen.
4. Typische Anwendungsfälle
- Enterprise Knowledge Assistant: Nutzen Sie mehrsprachige Funktionen zur Bereitstellung von Fragen und Antworten, Dokumentenabruf und Zusammenfassungen für globale Nutzer.
- Code- und Werkzeugaufrufe: Verwendet für Codevervollständigung, Skriptgenerierung und Multitool-Orchestrierung in Entwicklerszenarien.
- Multimodale Analyse: Beschreibung von Bildern, OCR-unterstütztes Verständnis und dann Kombinieren von Text für Argumentation und Frage-und-Antwort.
- Lokale Datenschutzszenarien: Ministral 3 läuft lokal für datenschutzsensible Datenanalyse und automatisierte Arbeitsabläufe.
- Anwendung im langen Kontext: Kombinieren Sie das Reasoning-Framework mit externem Abruf, um lange Dokumente zu lesen und komplexe Instruktionszerlegung zu erreichen.
5. Ökologie und konkurrierende Produkte
- Ökologische Integration: Es ist mit mehreren Cloud-Diensten und Inferenzplattformen verbunden und bietet offizielle Dokumentation, Governance und Compliance-Leitlinien, um einen einheitlichen Zugang für Unternehmen zu ermöglichen.
- Vergleich mit anderen großen Open-Source-Modellen: Auf derselben Parameterebene konzentriert sich die Ministral 3-Serie auf Kosteneffizienz- und Inferenz-Token-Zahlenvorteile; Als Open-Source-MoE-Modell ist Large 3 in Bezug auf mehrsprachige und instruktionskonforme Modell nahe an einem teilweise geschlossenen kommerziellen Modell.
- Beziehung zum Community-Modell: Es kann als ersetzbares Backend in den bestehenden RAG- und Agent-Frameworks verwendet werden, geeignet für eine reibungslose Migration von anderen LLMs, und der tatsächliche Effekt muss weiterhin mit der Geschäftsbewertung kombiniert werden.
6. Einschränkungen und Vorsichtsmaßnahmen
- Leistungsschwelle für große Modelle: Große 3 benötigen Multi-Card-High-End-GPUs oder Cloud-Inferenzdienste, und die lokalen Bereitstellungskosten sind hoch.
- Multimodale Fähigkeitsgrenze: Fehler können weiterhin beim Verständnis komplexer Bilder/Szenen auftreten, und für wichtige Dienste ist eine manuelle Verifikation erforderlich.
- Schätzung der Inferenzkosten: Obwohl weniger Token-Ausgaben betont werden, sind QPS und Budgetbewertung in hochzeitigen Nebenzeitszenarien dennoch notwendig.
- Modellaktualisierungsrhythmus: Neue Versionen und Gewichtsupdates könnten in Zukunft veröffentlicht werden, und Kompatibilitäts- und Migrationskosten müssen beachtet werden.
7. Projektadresse
https://mistral.ai/news/mistral-3
8. FAQ
F: Was ist die Open-Source-Lizenz des Mistral-3-Modells?
A: Die offizielle Behauptung, dass sowohl die Mistral Large 3 als auch die Ministral 3-Serie unter der Apache 2.0-Lizenz lizenziert sind und kommerziell sowie weitervertrieben werden können, aber dennoch die Lizenzbedingungen und Nutzungsvereinbarungen jeder Cloud-Plattform einhalten müssen.
F: Wie sollte ich mich zwischen Mistral Large 3 und Ministral 3 entscheiden?
A: Large 3 ist geeignet für Szenarien mit extrem hohen Anforderungen an Effekt- und Inferenzqualität sowie ausreichende Rechenleistung oder Budget; Die Ministral 3er Serie eignet sich besser für On-Premises-, Edge- und kostenempfindliche Anwendungen, mit inkrementeller Leistungssteigerungen und Ressourcenverbrauch in 3B/8B/14B.
F: Ist Mistral 3 für chinesische und mehrsprachige Anwendungen geeignet?
A: Der Offizielle betont gute Leistung in 40+ Sprachen, insbesondere in nicht-englisch/chinesischen Szenarien; In chinesischen und anderen Sprachunternehmen wird weiterhin empfohlen, spezielle Bewertungen durchzuführen und diese bei Bedarf in Kombination mit Domänendaten zu verfeinern.
F: Wie kann ich das Ministral 3 Modell vor Ort schnell erleben?
A: Sie können das entsprechende Modell von der Open-Source-Weight-Plattform herunterladen, es mit vLLM oder anderen Inferenz-Engines kombinieren und auf einer einzigen Maschine oder einer High-End-Consumer-GPU ausführen. Wenn Ressourcen begrenzt sind, bevorzuge die 3B- oder 8B-Version.
F: Wie gewährleistet Mistral 3 Datenschutz und Compliance?
A: Unternehmen sollten Protokolle, Desensibilisierungs- und Zugriffskontrollrichtlinien basierend auf ihren eigenen Anforderungen zur Datenkonformität konfigurieren und Privatisierung oder On-Premises-Bereitstellung in hochsensiblen Situationen priorisieren.



