I. Zusammenfassung
MiniMax M2 ist MiniMax‘ Open-Source-Modell für logisches Denken und Programmieren, positioniert als „Agent & Code Native“. In der offiziellen Einführung heißt es: „Basierend auf der Mixture-of-Experts (MoE)-Architektur verfügt das Modell über eine Gesamtparametergröße von ca. 230 B, aktiviert aber jeweils nur ca. 10 B Parameter. Dadurch wird eine hohe Inferenzqualität gewährleistet und gleichzeitig Inferenzkosten und Latenz reduziert.“ MiniMax gibt an, dass seine Leistung bei der Codegenerierung, der Planung von Long-Chain-Tools (Shell, Browser, Suche, Codeausführung usw.) und der Modifikation mehrerer Dateien der von handelsüblichen Assistenten nahekommt oder mit diesen vergleichbar ist. Der Preis beträgt ca. 8 % des Preises von Claude Sonnet, die Inferenzgeschwindigkeit ist etwa doppelt so hoch und der MiniMax Agent/API ist für begrenzte Zeit weltweit kostenlos verfügbar. Gewichte können direkt bezogen und lokal auf Hugging Face selbst gehostet oder über die offizielle API mit einer Inferenzschnittstelle ähnlich der von Anthropic/OpenAI abgerufen werden.
2. Kernfunktionen
- Entwickler-Workflow: Der Schwerpunkt liegt auf „End-to-End“, unterstützt das Lesen vorhandener Repositories, das Ändern mehrerer Dateien und das Ausführen, Testen und Korrigieren geschlossener Schleifen und zielt auf IDE/CI/agentenbasierte Codierungsassistent-Szenarien ab.
- Agent Native: Integrierte Richtlinien zur Tool-Nutzung und zum Aufrufformat, Unterstützung für die bedarfsgesteuerte Auslösung externer Tools (wie MCP, Shell, Browser, Suche, Codeausführung usw.) und Aufrechterhaltung der Zielkonsistenz in langen Aufgabenketten.
- Inferenzeffizienz: MoE ist so konzipiert, dass nur etwa 10 Bytes an Parametern für die Berechnung aktiviert werden. Ziel ist es, einen geringeren Speicherverbrauch und einen höheren Durchsatz auf privaten Clustern auf Verbraucher- und Unternehmensebene zu erreichen. vLLM und SGLang werden offiziell für die lokale Bereitstellung empfohlen, und Inferenz-Hyperparameter (wie Temperatur = 1,0, top_p = 0,95 und top_k = 20) werden bereitgestellt.
- Langfristige Kontext- und Mehrrundensteuerung: Ziel ist die „langfristige Toolchain“ und nicht die Beantwortung von Fragen in einer einzigen Runde. Der Schwerpunkt liegt auf dem stationären Verhalten bei komplexen Aufgaben mit mehreren Schritten (z. B. dem kontinuierlichen Debuggen desselben Projekts).
- Offen und kommerziell: Öffentliche Gewichte, Open-Source-Anweisungen im MIT-Stil (abhängig vom tatsächlichen Repository); und Bereitstellung eines kostenlosen Online-Inferenzportals zur schnellen Auswertung.
3. Installation
- Modell abrufen: Laden Sie die MiniMax-M2-Safetensor-Gewichte und die config.json aus dem Hugging Face-Repository herunter. Das Modell ist in Shards mit der MoE-Struktur gespeichert, daher müssen Sie alle Shards vollständig abrufen.
- Inferenz-Engine: Verwenden Sie vLLM oder SGLang, um lokale Inferenzdienste gemäß der offiziellen Anleitung zu starten. Beide unterstützen Szenarien mit hoher Parallelität und langem Kontext und eignen sich für das Hosting auf Enterprise-/lokalen GPUs.
- Inferenzparameter: Die offizielle Empfehlung lautet Temperatur = 1,0, top_p = 0,95 und top_k = 20. Eine mit gängigen Chat-Vorlagen kompatible Datei chat_template.jinja wird ebenfalls zur direkten Integration in die Standard-Chat-/Agent-Schleife bereitgestellt.
- API-Methode: Wenn Sie nicht selbst hosten möchten, können Sie direkt die Textgenerierungs-/Anthropics-artige API der MiniMax-Plattform aufrufen, die derzeit offiziell als „weltweit kostenlos für begrenzte Zeit“ beworben wird. Dies eignet sich für eine schnelle Bewertung von Latenz und Stabilität.
- Tool-Aufruf: Weitere Informationen finden Sie im offiziellen Tool-Aufruf-Handbuch. Das Modell gibt die erforderlichen Tools und ihre Eingabeparameter als strukturierte Parameter aus, die von einem externen Orchestrator ausgeführt werden können. Anschließend werden die Ergebnisse zurückgegeben.
Typische Anwendungsfälle
- Intelligenter Codierungsassistent: lokalisiert Fehler in vorhandenen Codebasen, schlägt Patches vor, ändert mehrere Dateien und generiert/aktualisiert Testfälle.
- Automatisierter Betriebs- und Wartungsagent: Führt eine mehrstufige Fehlerbehebung und Informationserfassung über eine Toolkette wie Shell/Browser/Suche durch und fasst dann die Ergebnisse zusammen.
- Langfristige F&E-Unterstützung: Zum Beispiel „einen minimal funktionsfähigen Dienst erstellen → eine Docker-Datei generieren → ein Bereitstellungsskript schreiben → Startprotokolle überprüfen → Fehler beheben“, wobei das Modell eine kontinuierliche Nachverfolgung statt einer einzigen Antwort bietet.
- Enterprise Private Deployment Assistant: Läuft im privaten Warehouse und in der privaten Abhängigkeitsumgebung des Unternehmens, um Compliance- und Datenschutzanforderungen zu erfüllen und gleichzeitig die Inferenz- und Tool-Planungsleistung nahezu kommerziell zu halten.
- IDE-Integration: Es kann in autonome agentenbasierte Entwicklungsumgebungen wie Cursor, Cline, Kilo Code und Droid für einen zyklischen „Schreiben-Ausführen-Ändern“-Ansatz eingebettet werden.
5. Ökosystem und Wettbewerbsprodukte
- Ökologie:
- MiniMax bietet einen offiziellen Agenten (MiniMax Agent) und eine einheitliche API, sodass M2 direkt als automatisierter Entwicklungs-/Fehlerbehebungsassistent verwendet werden kann.
- Auf Community-Ebene gab es Diskussionen über Kompatibilitätsanforderungen für Transformers/GGUF/Apple M-Serie GPUs (BF16/MPS), was darauf hindeutet, dass ein lokalisiertes Ökosystem Gestalt annimmt.
- Konkurrenzprodukte:
- Kommerzielle Closed-Source-Systeme: Claude Sonnet, GPT-4o/4.1-Serie usw. sind für ihre starke Code-/Tool-Nutzung bekannt, sind aber normalerweise teuer und Closed-Source;
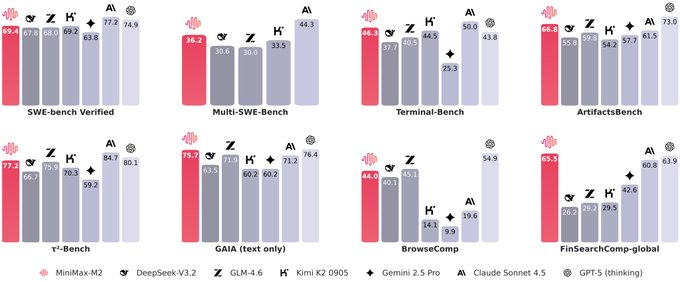
- Open-Source-Plattformen wie DeepSeek, Qwen und Llama entwickeln sich hinsichtlich Code und Agentenfunktionen rasant weiter. Die Verkaufsargumente des MiniMax M2 sind „230 Milliarden Gesamtparameter, 10 Milliarden Aktivierungen und ein nahezu kommerzielles Modellverhalten“ und betonen seine Vorteile hinsichtlich Inferenzpreis und Latenz. Wichtig zu beachten ist, dass die spezifischen Vergleichsdaten größtenteils offizieller/werblicher Natur sind und auf frühen Benchmarks basieren; die tatsächlichen Ergebnisse müssen in Ihren eigenen Anwendungsfällen überprüft werden.
VI. Einschränkungen und Vorsichtsmaßnahmen
- Die tatsächliche Leistung hängt vom Ausführenden ab: Die sogenannte „hohe Agentenleistung“ basiert auf der korrekten Ausführung und dem Ergebnisfeedback externer Tools. Wenn die Ausführungsschicht unzuverlässig ist, verringert sich der Gesamteffekt.
- Anbieterangaben vs. Geschäftsrealität: Beispielsweise ist „nur etwa 8 % der Kosten von Claude Sonnet und etwa doppelt so schnell“ nur die offizielle Positionierung. Kosten und Latenz hängen weiterhin von der Hardware, der Batchgröße, der Kontextlänge und der Parallelitätsstrategie ab.
- Langfristige Aufgabenkonsistenz: Bei extrem langen Aufgaben mit mehreren Zweigen erfordert die Sicherstellung, dass das Modell stets sicher, konform und frei von destruktiven Anweisungen bleibt, weiterhin zusätzliche Berechtigungen und Prüfungen auf Unternehmensseite.
- Lokaler Bereitstellungsschwellenwert: Obwohl der Aktivierungsparameter etwa 10 B beträgt, beträgt die Gesamtgewichtsskala 230 B MoE-Shards, was immer noch Anforderungen an Bandbreite, Videospeicher und Ladezeit stellt.
- Compliance und Daten: Die Verwendung der automatischen Codeänderung/Shell-Ausführung in privaten Unternehmensszenarien erfordert strenge Mindestberechtigungen und Prüfaufzeichnungen, um Fehlfunktionen in der Produktionsumgebung zu vermeiden.
7. Projektadresse
https://github.com/MiniMax-AI/MiniMax-M2
8. Häufig gestellte Fragen
F: Ist MiniMax M2 wirklich „Open Source und kommerziell erhältlich“?
A: Das offizielle Repository und Hugging Face stellen vollständige Gewichte zum Download bereit, die als offene Gewichte gekennzeichnet sind und eine lokale Verwendung ermöglichen. Die Lizenz wird derzeit als MIT-nah/permissiv beschrieben. Vor der Verwendung sollten Sie die Lizenz dennoch genau prüfen, insbesondere die kommerziellen und Weiterverbreitungsbedingungen.
F: Was bedeutet „230 B Gesamtparameter / 10 B Aktivierungsparameter“?
A: Dies ist ein typischer MoE-Ansatz (Mixture-of-Experts): Das Modell enthält eine große Anzahl von Experten, von denen jedoch nur eine kleine Anzahl für jede Inferenz vorgesehen ist. Dies reduziert die Rechenkosten auf ca. 10 Milliarden, während gleichzeitig die hohe Leistungsfähigkeit erhalten bleibt, der Durchsatz verbessert und der Stückpreis der Inferenz gesenkt wird.
F: Unterstützt es Tool-Aufrufe/MCP-/Browser-/Shell-Aufrufe?
A: Das offizielle Tool bietet einen Tool Calling Guide. Das Modell kann automatisch die aufzurufenden Tools und Parameter bereitstellen und in externe Executoren wie MCP, Shell, Retriever, Browser usw. integriert werden, was für automatisierte Agenten geeignet ist.
F: Kann ich es online erleben, ohne es selbst zu hosten?
A: Ja. Die MiniMax-Plattform bietet die MiniMax M2 API, die weltweit für begrenzte Zeit kostenlos verfügbar ist. Diese eignet sich für eine frühe Evaluierung und erfordert keinen GPU-Cluster.
F: Wie unterscheidet es sich von Claude Sonnet?
A: MiniMax behauptet, in Bezug auf Code, mehrstufigen Tool-Einsatz und Inferenzgeschwindigkeit den gängigen Closed-Source-Modellen nahe zu kommen oder sie sogar zu übertreffen. Der Inferenzpreis liegt bei etwa 8 % des Preises von Sonnet, und die Geschwindigkeit ist etwa doppelt so hoch. Bitte beachten Sie, dass es sich hierbei um offizielle Benchmarks handelt; die tatsächlichen Kosten schwanken je nach Anrufvolumen und Hardware.