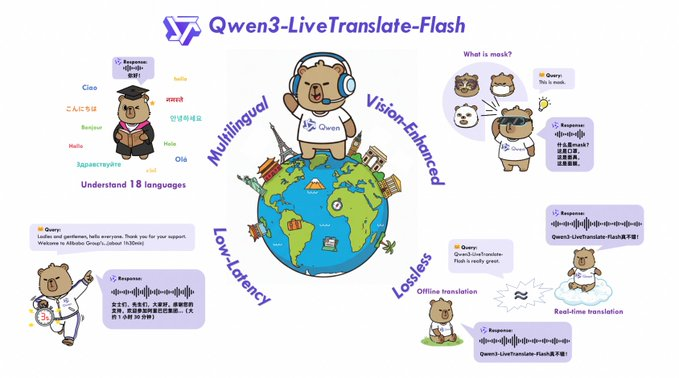
Tongyi Qianwen gab die Markteinführung von Qwen3-LiveTranslate-Flash bekannt, einem multimodalen Simultandolmetschmodell in Echtzeit, das für die persönliche Kommunikation und Offline-Veranstaltungen entwickelt wurde. Offiziellen Daten zufolge kann das Modell die Erkennung und Übersetzung innerhalb von etwa 3 Sekunden End-to-End-Latenz abschließen, 18 Sprachen erkennen , 6 Dialekte verstehen und Sprache in 10 Sprachen ausgeben und dabei einen natürlichen und ausdrucksstarken Klang liefern. Das Modell legt den Schwerpunkt auf „visuell verbessertes Verständnis“ und kann Lippenform, Gesten, Bildschirmtext und Entitätserkennung kombinieren und so auch in lauten Umgebungen eine robuste Leistung aufrechterhalten.
Für den Zugriff bietet Alibaba Cloud DashScope die Qwen3-LiveTranslate-Flash-Realtime- Schnittstelle und Anweisungen zur Ratenbegrenzung sowie eine Online -Demo von Hugging Face für eine einfache Erfahrung. Offizielle Kanäle beschreiben es als Echtzeit-Interpretationslösung mit „Offline-Genauigkeit“, wobei die spezifische Leistung je nach Eingabegerät, Szenenrauschen und Netzwerkbedingungen variiert. Mehrsprachigkeit und Latenzmetriken unterliegen der Produktdokumentation und nachfolgenden technischen Berichten.
Häufig gestellte Fragen
F: Welche Sprachen und Ausgaben werden unterstützt?
A: Erkennt 18 Sprachen, versteht 6 Dialekte und kann Sprache in 10 Sprachen ausgeben; eine vollständige Liste finden Sie in der Model Studio-Dokumentation.
F: Wie steht es um Latenz und Robustheit?
A: Die offizielle Schätzung liegt bei etwa 3 Sekunden von Ende zu Ende. Die Kombination von Lippenlesen, Gesten und Bildschirmlesen kann die Stabilität in lauten Umgebungen verbessern. Die tatsächliche Zeit hängt vom Gerät und Netzwerk ab.
F: Wie kann man es erleben oder nennen?
A: Sie können die Demo auf Hugging Face erleben; die Produktionsintegration kann über die Echtzeitschnittstelle von Alibaba Cloud DashScope erreicht werden.
F: Ist es Open Source?
A: Es wird in Form einer API bereitgestellt und sein volles Gewicht wird derzeit nicht offengelegt; zugehörige Beispiele und Demonstrationen werden synchron im GitHub/HF/ModelScope-Ökosystem aktualisiert.
F: Welche Szenarien sind anwendbar?
A: Echtzeitanwendungen wie sprachübergreifende persönliche Kommunikation, Konferenzdolmetschen, Tourismusdienste, Synchronisation von Inhalten und Live-Simultandolmetschen.