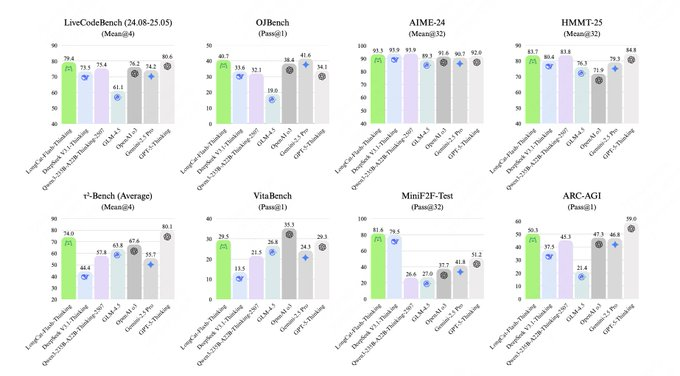
LongCat-Flash-Thinking kombiniert KI mit MoE, asynchronem RL und agentennativen Tools und erreicht so hochmoderne Leistung in Logik-, Mathematik-, Codierungs- und Agentenaufgaben. AIME25 erreicht eine hohe Genauigkeit mit weniger Token und eignet sich daher für Unternehmen, um qualitativ hochwertige Inferenz und eine stabile Implementierung zu geringen Kosten zu erreichen. I. Warum sich eine sofortige Bereitstellung lohnt 1. Highlights der Architektur: Dynamische MoE-Aktivierung (LongCat-Flash-Thinking) KI aktiviert Experten nach Bedarf über MoE, wodurch tiefe Inferenz erhalten bleibt und gleichzeitig Inferenz-Overhead und Speichernutzung reduziert werden, was die Zerlegung von Problemen mit langen Ketten und interpretierbare Ausgaben unterstützt. 2. Effizienz und Kosten: AIME25 spart Token (LongCat-Flash-Thinking) KI nutzt native Tools und agentenfreundliche Strategien, um die Anzahl der Token, die zum Erreichen höchster Genauigkeit erforderlich sind, deutlich zu reduzieren, sowohl Inferenzkosten als auch Latenz zu optimieren und Onlinedienste im großen Maßstab zu ermöglichen. 3. Infrastruktur: Asynchrones RL, dreifache Beschleunigung (LongCat-Flash-Thinking). Asynchrones RL entkoppelt Sampling und Optimierung, um Durchsatz und Stabilität zu verbessern. Es kombiniert Datenwiedergabe und automatische Auswertung, um Iterationszyklen zu verkürzen und einen schnellen geschlossenen Kreislauf vom Training bis zur Bereitstellung zu bilden.
II. Implementierungsmethoden und Szenarioliste
1. Bereitstellungspfad (LongCat-Flash-Thinking)
(1) Argumentationsrahmen: Priorisieren Sie vLLM oder SGLang, kombiniert mit KV Cache und Stapelverarbeitung
(2) Ressourcenstrategie: Einfache Aufgaben erfordern langes Nachdenken, komplexe Aufgaben erfordern Nachdenken und Werkzeuge
(3) Beobachtungsindikatoren: Zeichnen Sie Token, Verzögerungen, Erfolgsraten auf und automatisieren Sie die Parameteranpassung
2. Eingabeaufforderungswörter und Agenten-Pipeline (LongCat-Flash-Thinking)
(1) Bestimmen Sie, ob ein Tool benötigt wird, bevor Sie den Funktionsaufruf eingeben
(2) Legen Sie feste Eingabe- und Ausgabevorlagen für Mathematik und Code fest
(3) Konfigurieren Sie Timeout-, Wiederholungs- und Fallback-Pfade für mehrere Tools gleichzeitig
(3) Typische Anwendungen (LongCat-Flash-Thinking)
a. Codereparatur und Regressionsstandort
b. Prozessbasierter Agent mit Suche und Berechnung
c. Berichterstellung und Automatisierung komplexer Fragen und Antworten
III. Wichtige Punkte für Leistungsmessung und Governance
1. Leistung (KI + LongCat-Flash-Thinking)
Bewerten Sie anhand von Genauigkeit, Erklärbarkeit der Schritte und Erfolgsrate des Agenten, mit Schwerpunkt auf langfristiger Verbindungsstabilität und Wiederspielbarkeit.
2. Kosten (KI + LongCat-Flash-Thinking)
Überwachen Sie Token pro Aufgabe, Speicherspitzen und End-to-End-Latenz, um A/B-Vorteile zu quantifizieren und eine kontinuierliche Optimierung zu ermöglichen.
3. Governance (KI + LongCat-Flash-Thinking)
Konsolidieren Sie einheitliche Eingabeaufforderungsvorlagen, Datenversionen und Protokolle, um die Eingabeaufforderungssensitivität und das Driftrisiko zu reduzieren.
Häufig gestellte Fragen (Q&A)
F: Wie ist die Leistung von LongCat-Flash-Thinking bei KI-Aufgaben?
A: Es zählt zu den führenden Open-Source-SOTA-Systemen in den Bereichen Logik, Mathematik, Programmierung und Agentenaufgaben und legt den Schwerpunkt auf stabiles Denken und reproduzierbare Auswertung.
F: Warum ist es in AIME25 effizienter?
A: Wir nutzen native Tools und agentenfreundliche Strategien, um Entscheidungen zu priorisieren, bevor wir sie ausführen. Dadurch wird ineffektives, langfristiges Denken reduziert und die Inferenzkosten bei gleichbleibender Genauigkeit gesenkt.
F: Was sind die direkten Vorteile von asynchronem RL für die Entwicklung?
A: Verbesserter Trainingsdurchsatz, stabilere Konvergenz und schnellere Iteration helfen uns, Modellverbesserungen schnell online zu stellen und deren Vorteile zu überprüfen.
F: Wie können Unternehmen schnell loslegen und die Kosten kontrollieren?
A: Wählen Sie eine Inferenz-Engine mit hohem Durchsatz, Aktivieren Sie Batching und Caching. Verwenden Sie einen Denkschalter, um den Schwierigkeitsgrad von Aufgaben zu differenzieren. Überwachen Sie Token und Latenz kontinuierlich und passen Sie Parameter automatisch an.