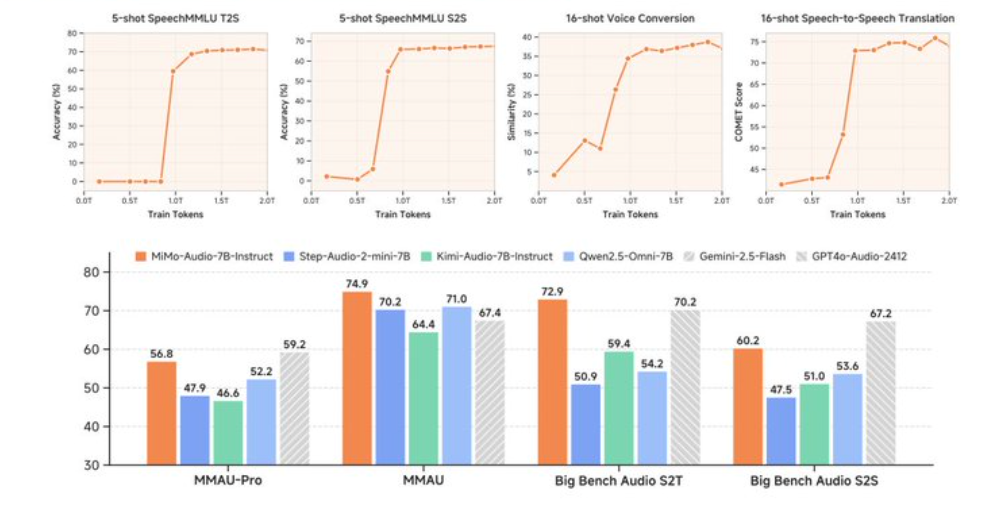
Firecrawl v2.3.0 bietet wichtige Upgrades für KI-Crawling und -Parsing: neue YouTube-Unterstützung, ODT- und RTF-Parsing und eine etwa 50-fache Beschleunigung für DocX-Parsing. Es umfasst auch Enterprise Auto-Recharge, ein optimiertes Playground-Erlebnis und verbessertes Self-Hosting, wodurch es ein sofortiges Upgrade für KI-Agenten, RAGs und Datenpipeline-Teams darstellt. I. Übersicht über die wichtigsten Updates: Von „leistungsfähig“ zu „schnell“ 1. YouTube-Unterstützung KI-Crawling-Schlüsselwörter: Firecrawl, YouTube und Audio/Video-zu-Text. Videoseiten können jetzt direkt gecrawlt und in Language Library Manager-freundliches Markdown oder strukturierte Daten konvertiert werden, was Zusammenfassungen, Schlüsselpunktextraktion, Kapitelindizierung und multimodale Fragen und Antworten erleichtert. 2. Verbesserungen beim Dokument-Parsing: ODT- und RTF-Unterstützung und Geschwindigkeitsverbesserungen beim DocX-Parsing. KI-Parsing-Schlüsselwörter: ODT, RTF und DocX. Neues ODT- und RTF-Parsing deckt mehr Enterprise-Legacy-Formate ab; Die Docx-Analysegeschwindigkeit wird um etwa das 50-fache erhöht und die Stapelextraktion langer Dokumente sowie die Tabellenextraktion werden erheblich beschleunigt, was für den Kaltstart von Wissensdatenbanken und die Compliance-Archivierung geeignet ist.
(1) Playground und Self-Hosting
Schlüsselwörter für KI-Engineering: Playground, Self-Hosting. Die Interaktion mit dem Playground ist reibungsloser und erleichtert die schnelle Iteration von Wörtern und Richtlinien. Verbesserungen beim Self-Hosting reduzieren Reibungsverluste bei Bereitstellung und Betrieb und sind in privaten Szenarien stabiler.
II. Unternehmensorientiert: Kosten, Stabilität und Skalierbarkeit
- Automatisches Aufladen für Unternehmen
Schlüsselwörter für KI-Abrechnung: Automatisches Aufladen, Unternehmenskontingent. Das automatische Auffüllen von Kontingenten zur Vermeidung von Aufgabenunterbrechungen eignet sich für umfangreiches Crawling, geplante Jobs und Spitzenverkehr am Wochenende. Die Kombination von Ratenbegrenzung und Warteschlangenstrategien gewährleistet die Stabilität der Produktionslinie.
- Praktische Implementierung von RAG und Agenten
Schlüsselwörter für KI-Anwendungen: RAG, Agenten, strukturierte Extraktion. In Kombination mit Suche und Crawling wird zunächst Firecrawl verwendet, um die vollständige Seite abzurufen. Anschließend werden mithilfe der Extraktionsvorlage JSON-Fragmente generiert. Anschließend werden die Vektorbibliothek und die relationale Bibliothek direkt aufgerufen, um den geschlossenen Kreislauf „Crawlen-Extrahieren-Abrufen-Fragen-Beantworten“ zu erreichen.
(1) Vorschläge für Upgrades und Kompatibilität
Schlüsselwörter für die KI-Migration: v2.3.0, API-Kompatibilität. Die Produktionsumgebung aktiviert zunächst v2.3.0 im Graustufenprojekt, um Durchsatz, Erfolgsrate und Kosten von YouTube und dem neuen Parser zu bewerten. Die Rollback-Strategie und die Wiederholungswarteschlange der alten Version werden beibehalten, um die Kontinuität der Aufgaben zu gewährleisten.
Drei typische Verwendungen: sofort einsatzbereit
- Content-Team
Schlüsselwörter für den KI-Workflow: Videozusammenfassung, Kapitelindex. Durchsuchen Sie YouTube-Podcasts und -Vorlesungen im Batch, geben Sie Zeitstempelzusammenfassungen, Nomenlisten und Zitatsegmente aus und verbessern Sie die Effizienz der sekundären Bearbeitung und Verteilung.
- Betriebs- und Risikokontrolle
Schlüsselwörter zur KI-Überwachung: öffentliche Meinung zur Marke, Einhaltung von Richtlinien. Überwachen Sie offizielle Websites, Foren und Dokumentaktualisierungen und verwenden Sie strukturierte Extraktion, um Preisänderungen, neue Begriffe und Treffer sensibler Wörter zu identifizieren.
(1) Enterprise Knowledge Base
Schlüsselwörter zu KI-Daten: heterogene Dokumente, Batch-Speicherung. Einheitliches Parsen von docx-, odt-, rtf- und Webseiten, Bereinigung auf ein einheitliches Schema und Starten der RAG-Wissenssuche und des Frage-und-Antwort-Assistenten.
Häufig gestellte Fragen (Q&A)
F: Welche KI-Szenarien eignen sich für die YouTube-Unterstützung von Firecrawl v2.3.0?
A: Geeignet für KI-Zusammenfassungen, Kapitelnavigation, Wissenskarten und semantische Abfrage. In Verbindung mit RAG können mehrere Frage-und-Antwort-Runden und Vergleiche mehrerer Quellen direkt durchgeführt werden.
F: Welchen Wert bringt die 50-fache Beschleunigung für odt-, rtf- und docx-Dateien Unternehmen?
A: KI-gestützte Stapelextraktion beschleunigt die Stapelverarbeitung, verkürzt die Kaltstartzeit für historische Dokumente erheblich und senkt die Kosten für die Archivierung der Dokumentenkonformität und den Aufbau einer Wissensdatenbank.
F: Wie kontrolliert Enterprise Auto-Recharge Budgetrisiken?
A: Durch das Festlegen von Obergrenzen, die Zuweisung von Kontingenten und Ratenbegrenzungen nach Projekten und die Kombination von fehlgeschlagenen Wiederholungs- und Deduplizierungsstrategien gewährleisten wir „kontinuierliche Bestellungen ohne Kontrollverlust“.
F: Erleichtert die Self-Hosting-Erweiterung die Einhaltung privater Vorschriften?
A: Eine einfachere Bereitstellung und Überwachung, kombiniert mit den Intranet- und Datendesensibilisierungsrichtlinien des Unternehmens, erfüllt strenge Anforderungen an Datensouveränität und -prüfung.