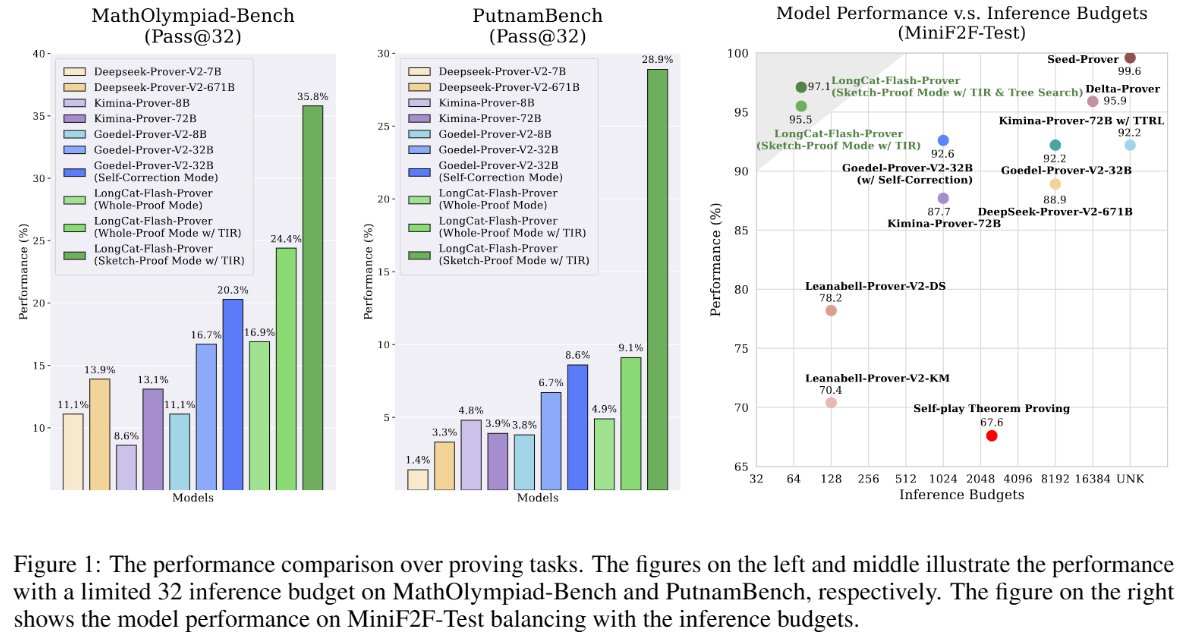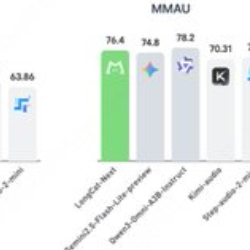
- Zusammenfassung
LongCat-Next ist ein Open-Source-basiertes, diskretes, natives autoregressives multimodales Modell von Meituans LongCat-Team mit dem Ziel, Text, Bilder und Audio im selben Rahmen zu vereinen. Das Projekt verwendet die MoE-Architektur mit einem Gesamtparameter von etwa 68,5 B und einem Aktivierungsparameter von etwa 3 B, was die kollaborative Vollständigkeit von "Sehen, Zeichnen und Sprechen" in einem einzigen diskreten Token-Raum betont und so Verständnis-, Generierungs- und Interaktionsmöglichkeiten für industrielle multimodale Szenarien bietet.
- Kernmerkmale
- DiNA-Paradigma: Erweiterung der Next-Token-Vorhersage von der Sprache auf native Multimodalität, indem Text, Bilder und Audio in einem gemeinsamen diskreten Token-Raum vereinigt werden.
- dNaViT: Unterstützung der diskreten Codierung und Rekonstruktion von Bildern mit beliebiger Auflösung, wobei sowohl visuelles Verständnis als auch visuelle Generierung berücksichtigt werden.
- Visuelles Verstehen: Umfasst Aufgaben wie OCR, Diagrammverständnis, GUI-Parsing und Dokumentenanalyse und verfügt über bestimmte MINT-Denkfähigkeiten.
- Visuelle Generierung: Es unterstützt beliebige Auflösungsgenerierung bei hohem Kompressionsverhältnis, was in Textrendering-Szenarien sehr wettbewerbsfähig ist.
- Sprachfunktionen: Unterstützung für Audioverständnis, latenzarte Sprachinteraktion und anpassbares Stimmklonen.
- Installation
- Hol den Code vom offiziellen GitHub und erstelle eine laufende Umgebung gemäß den Anweisungen des Repositorys.
- Empfohlene Umgebungen sind Python 3.10 und höher, Torch 2.6 und höher, Transformers 4.57.6 und höher sowie Accelerate ab 1.10.0.
- Nach der Installation der Anforderungen und ergänzenden Abhängigkeiten laden Sie die LongCat-Next-Gewichte aus dem Hugging Face.
- Offizielle Beispiele zeigen, dass lokale Inferenz auf Basis von Transformers in der Regel mindestens 3 GPUs mit 80 GB Videospeicher benötigt.
- Typische Anwendungsfälle
- Dokumentenverständnis: Identifikation und Analyse von Rechnungen, Formularen, Berichten, Screenshots und anderen Inhalten.
- Schnittstellenanalyse: Verstehen Sie die Softwareoberfläche, das Button-Layout und den Interaktionsprozess.
- Multimodale Fragen und Antworten: Verwenden Sie Text, Bilder und Audio als einheitliche Eingaben für umfassende Argumentation.
- Bildgenerierung: Erstellen Sie Poster, Bilder mit Text und multi-auflösende visuelle Inhalte.
- Stimminteraktion: Verstehen Sie die Antwort auf Sprachfragen, Sprach-zu-Sprache und maßgeschneiderte Sprachsynthese.
- Ökologie und konkurrierende Produkte
- Im Bereich Ökologie hat LongCat-Next GitHub, Hugging Face, Online-Demos, Blog-Einführungen und Portale für technische Berichte bereitgestellt.
- Im Vergleich zum gängigen Schema "visueller Encoder oder Audio-Encoder in LLM eingesteckt" legt LongCat-Next Wert auf native einheitliche Modellierung.
- Im Vergleich zu Single-Point-optimalen dedizierten Visionsmodellen, Bilderzeugungsmodellen oder Sprachmodellen hat es den Vorteil eines einheitlichen Frameworks und Multitask-Abdeckungs, allerdings auf Kosten höherer Bereitstellungskomplexität.
- Einschränkungen und Vorsichtsmaßnahmen
- Die Bereitstellungsschwelle ist hoch, und die Anforderungen an Videospeicher, Bandbreite und Gesamtrechenleistung sind offensichtlich.
- Visuelle Generierung und Sprachklonfähigkeiten erfordern zusätzliche Berücksichtigung von Sicherheits-, Urheberrechts- und Compliance-Fragen in praktischen Anwendungen.
- Obwohl der diskrete visuelle Weg durch die Einheit von Verständnis und Erzeugung gekennzeichnet ist, sollte der spezifische Effekt dennoch der tatsächlichen Messung des Zielunternehmens unterliegen.
- Als neues Open-Source-Projekt könnten sich seine Schnittstellen, Abhängigkeiten und Best Practices weiterhin verändern.
- Projektadresse
https://github.com/meituan-longcat/LongCat-Next
- Häufig gestellte Fragen
F: Was ist LongCat-Next?
A: LongCat-Next ist ein Open-Source-basiertes, diskretes, native autoregressives multimodales Modell aus Meituans LongCat-Team, das Text, Bilder und Audio einheitlich verarbeitet.
F: Was ist DiNA, die Kerntechnologie von LongCat-Next?
A: DiNA ist ein Modellierungsparadigma, das Next-Token-Vorhersage auf native Multimodalität erweitert und Sprache, Bilder und Audio mit einem gemeinsamen diskreten Token-Raum vereint.
F: Was macht LongCat-Nexts dNaViT?
A: dNaViT ist ein Modul zur Diskretisierung und Rekonstruktion von LongCat-Next, das das Verständnis und die Erzeugung von Bildern jeder Auflösung unterstützt.
F: Für welche Anwendungen eignet sich LongCat-Next?
A: Es eignet sich für Szenarien wie OCR, Graphenverstehen, GUI-Parsing, Dokumentenanalyse, multimodale Fragenbeantwortung, Bildgenerierung und Sprachinteraktion.
F: Gibt es hohe Hardwareanforderungen für LongCat-Next On-Premises-Implementierungen?
A: Ja, offizielle Beispiele zeigen, dass die Implementierung höhere Anforderungen an GPU-Videospeicher hat, was sie für Hochleistungsumgebungen mit hoher Rechenleistung besser geeignet macht.