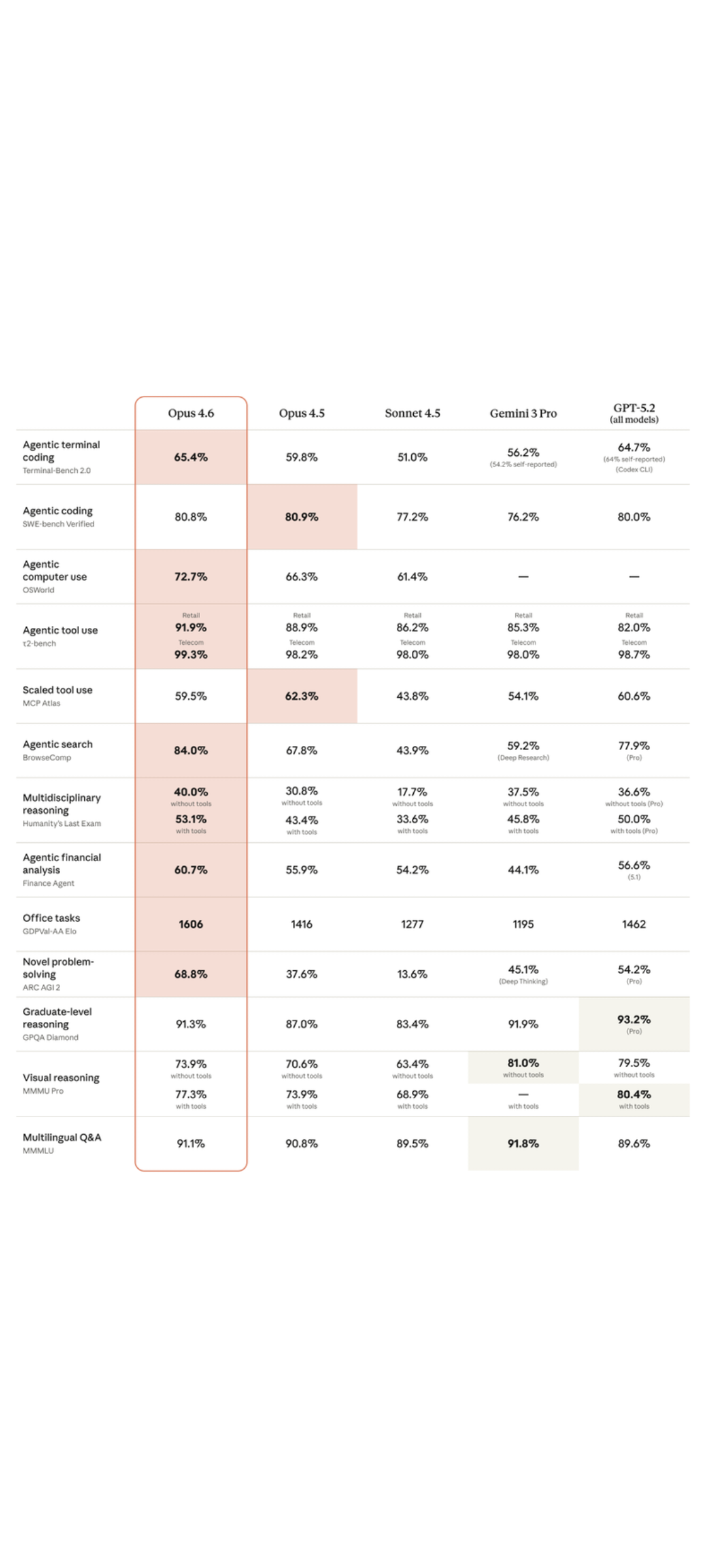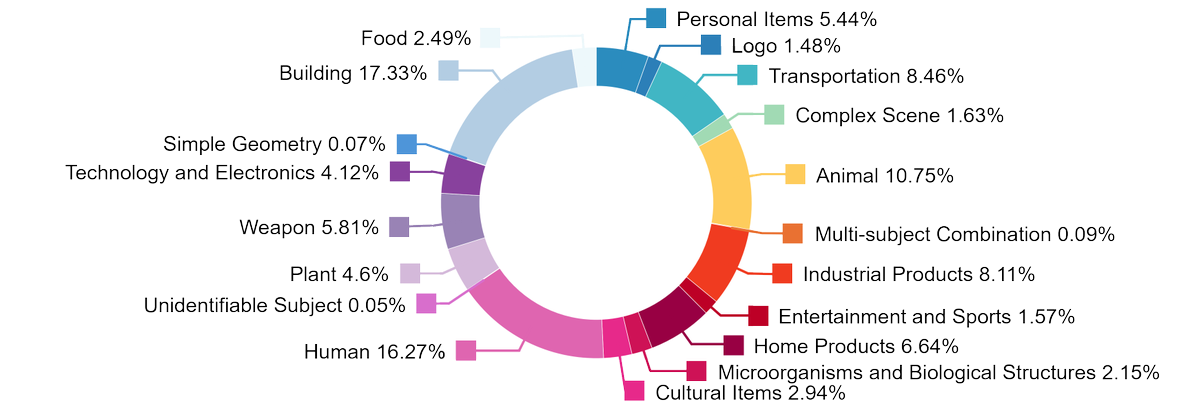
1. Zusammenfassung
HY3D-Bench ist ein open-source, einheitliches 3D-Asset-Datenökosystem des Hunyuan-Teams von Tencent mit dem Ziel, die häufigen Schmerzpunkte wie "Datenknappheit, hoher Rauschen und inkonsistenter Evaluation" im Bereich der 3D-Generierung zu lindern. Das Projekt veröffentlicht drei Arten komplementärer Datenteilsätze gleichzeitig: Vollebene (252K+ vollständige Objekte), Teilebene (240K+ komponentenebene strukturelle Zerlegung) und Synthetisch (125K+ AIGC synthetische Langschwanzkategorien) und bietet ein leichtes und reproduzierbares Basismodell, Hunyuan3D-Shape-v2-1 Small (0,8B).
2. Kernmerkmale
- Trainingsreife Qualität: Das Netz wird gereinigt, normalisiert und wasserdicht/manifold behandelt, um Trainingsgeräusche wie Nicht-Manifold und Lochbrechen zu reduzieren.
- Vereinheitlichtes Format und Metadaten: Verschiedene Teilmengen sind in Dateiorganisation und Feldern konsistenter, was den Aufbau von Datenpipelines und Evaluationsprozessen erleichtert.
- Vollwertige vollständige Objekte: einschließlich wasserdichter Meshes, Multiview-Renderings und Sampling-Punkte, geeignet für Single-View-zu-3D-Rekonstruktion und Generierungstraining.
- Komponenten-Ebene-Dekomposition: Bereitstellung von Komponentenlabels, komponentenunabhängige Meshes und Komponenten-Assembly-Rendering sowie Unterstützung für feingranulare steuerbare Generierung, Strukturbearbeitung und roboterbezogene Operationen.
- Synthetische Long-Tail-Komplettierung: Deckt 1.252 feinkörnige Unterklassen, Zielkategorie-Ungleichgewicht und Long-Tail-Generalisierung ab, geeignet für Datenaufstockung und Zero-Shot-Evaluations-Supplementation.
- Leichtgewichtige Basislinie: Bietet eine DiT-Form-Basislinie im Maßstab von 0,8 Milliarden (2048/4096 Token-Version), um die Schwelle für Reproduzierbarkeitsexperimente zu senken.
3. Installation
- Umgebungsvorbereitung: Es wird empfohlen, Linux + Python (mit PyTorch/gängigen Deep-Learning-Stacks) zu verwenden und genügend Festplatten zu reservieren (voll etwa 11TB, Teil etwa 5TB, synthetisch etwa 6,5TB).
2. Daten abholen (empfohlen): Nach der Installation der Hugging Face CLI verwenden Sie hf download, um die volle Menge abzurufen oder in Teilmengen herunterzuladen.
- Baseline-Reproduktion: Klonen Sie das Repository, installieren Sie Abhängigkeiten gemäß der Beschreibung des Baselines-Verzeichnisses und konfigurieren Sie den Datenpfad, um das Trainings-/Evaluationsskript zu starten.
4. Typische Anwendungsfälle
- 3D Generation Training Set: eine einheitliche Trainingsdatenquelle für 3D-Generierungsmodelle wie Diffusion/GAN/Autoregression.
- Single/Multi-View zu 3D: Rekonstruktion und Bewertung mit standardisierter Rendering-Perspektive und geometrischer Supervision.
- Steuerbare Bearbeitung und strukturelle Konsistenz: Verwenden Sie Raster und Beschriftungen auf Komponentenebene, um "nach Teil zu generieren/ersetzen/wieder zusammenzusetzen".
- Roboter- und Simulations-Asset-Bibliothek: Unterstützung von Erschwinglichkeitslernen, Ergriffsplanung und interaktiver Simulation mit Komponentenzerlegung.
- Long-Tail- und Kategorienbalance: Verwendung synthetischer Assets, um seltene Kategorien zu vervollständigen und so die Robustheit und Erklärbarkeit von Verallgemeinerungsvergleichsexperimenten zu verbessern.
5. Ökologie und konkurrierende Produkte
- Ökologie: GitHub stellt Datenbeschreibungen und Basiscode bereit; Hugging Face bietet Datensatz-Hosting und Baseline-Weight-Downloads für eine einfache Reproduzierbarkeit durch die Community.
- Konkurrenzprodukte/Steuerungen: Gängige 3D-Asset-Bibliotheken oder groß angelegte 3D-Datensätze sind maßstabsstark ausreichend, es kann jedoch Probleme wie Rauschen, unzureichende strukturelle Granularität und unterschiedliche Bewertungskaliber geben. Der Unterschied zwischen HY3D-Bench liegt in der Kombination aus "trainingsbereiter Reinigung + Komponentenstruktur + synthetischer Long-Tail-Komplettierung + reproduzierbarer, leichter Baseline". Die tatsächlichen Vor- und Nachteile werden weiterhin basierend auf deinen Aufgabenindikatoren und Ablationsexperimenten empfohlen.
6. Einschränkungen und Vorsichtsmaßnahmen
- Hohe Speicher- und Bandbreitenkosten: Das gesamte Datenvolumen ist groß, daher wird empfohlen, schrittweise nach Subset/On-Demand herunterzuladen und zu trainieren.
- Lizenzierung und Compliance: Daten können aus Multi-Source-Verarbeitung und -Weiterverteilung stammen, daher sollten Sie unbedingt die Lizenzdatei des Repositorys sowie die Quell-/Verteilungsanweisungen für jede Teilmenge lesen, um die Grenzen zwischen kommerzieller Nutzung und Weiterverteilung zu bestätigen.
- Anwendungsbereich der Komponentenkennzeichnung: Komponentendefinition und Granularität können je nach Kategorie variieren, und die Designindikatoren sollten bei der Cross-Class-Generalisierung oder der Bewertung der strukturellen Konsistenz sorgfältig gestaltet werden.
- Synthetische Datenverzerrung: AIGC-Vermögenswerte können Stilverteilungsverschiebungen bewirken, und es wird empfohlen, diese zusammen mit realen Datenmischungsverhältnissen und Strategien zur Kategorien-Neubeschlagnahme zu abschließen.
7. Projektadresse
https://github.com/Tencent-Hunyuan/HY3D-Bench
8. Häufig gestellte Fragen
F: Welche Teilmengen (Full-level/Part-level/Synthetic) sind im HY3D-Bench-Datensatz enthalten?
A: Full-Level bietet 252K+ vollständig wasserdichte Objekte mit Render-/Abtastpunkten; Teilebene bietet 240K+ Teilebene-Dekomposition und Assemblerrendering; Synthetic bietet 125.000+ synthetische Vermögenswerte in 1.252 feinkörnigen Unterklassen.
F: Wie kann ich HY3D-Bench herunterladen, um Speicherplatz zu sparen?
A: Ich bevorzuge es, die per-Pfad-Include-Methode von Hugging Face zu verwenden, um nur full/**, part/** oder synthetic/** zu ziehen und mit einer kleinen Teilmenge oder Validierungsmenge zu beginnen.
F: Wie ist die Beziehung zwischen Hunyuan3D-2.1-Small / Hunyuan3D-Shape-v2-1 Small Baseline?
A: Die Arbeit erwähnt die Verwendung von Hunyuan3D-2.1-Small zur empirischen Verifikation; Die Datenseite bietet außerdem ein leichtes Grundgewicht der Form (0,8B) basierend auf vollständigem Training. Es wird empfohlen, die Reproduktionsexperiment-Einstellungen basierend auf der Beschreibung der Basislinien des Repositorys zu wählen.
F: Können Daten auf Teilebene "einzeln generiert/bearbeitet" werden?
A: Es kann als Benchmark für Trainingsüberwachung und -bewertung verwendet werden (Teilbeschriftung + Teil Mesh + Montagerendering), aber der Unterschied in der Teildefinition und Kategorie beeinflusst den steuerbaren Effekt und muss mit dem Aufgabendesign und den Indikatoren abgestimmt werden.
F: Ist die Synthetische Teilgruppe für direkte Master-Trainings geeignet?
A: Die gebräuchlichere Verwendung ist das Ausfüllen des langen Schwanzes und die Datenerweiterung; Wenn er als Haupttrainingsset verwendet wird, wird empfohlen, auf die Verteilungsverzerrung zu achten und sie mit der realen Teilmenge für Kontrollexperimente zu mischen.