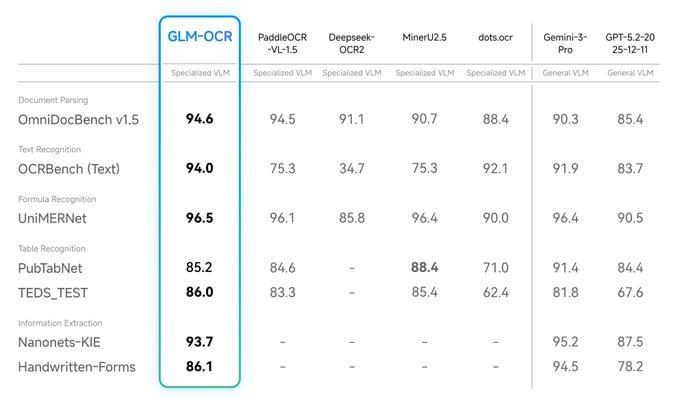
Z.ai veröffentlichte das multimodale OCR-Modell GLM-OCR, das Gewichte auf Hugging Face öffnet und Online-Erfahrungen sowie API-Aufrufmethoden bereitstellt. Offiziell hat das Modell nur etwa 0,9 Milliarden Parameter, aber es hat führende Leistungen bei komplexen Dokumentenverständnisaufgaben erzielt, die Szenarien wie Formelerkennung, Tabellenerkennung und Schlüsselinformationsextraktion abdecken.
Was die API-Nutzung betrifft, unterstützt GLM-OCR die Eingabe von PDF und Bildern (JPG/PNG) mit einem einzelnen Bild von nicht mehr als 10 MB, PDF maximal 50 MB und maximal 100 Seiten. Die Ausgabe kann Markdown-Ergebnisse und Layoutdetails für Dokumentparsing, Dateneingabe und RAG-Dokumentvorverarbeitung enthalten. Der tatsächliche Effekt wird weiterhin von der Scanqualität, der Schriftmischung, der Siegelverdichtung und der Layoutkomplexität beeinflusst, und es wird empfohlen, Probentests und Datenschutz-Compliance-Prüfungen in der Produktionsumgebung durchzuführen.
FAQs
F: Welche Probleme löst GLM-OCR hauptsächlich?
A: GLM-OCR eignet sich für OCR und das Verständnis komplexer Dokumente, einschließlich Text, Tabellen, Formeln und Informationsextraktion.
F: Welche Eingabe- und Größenbeschränkungen unterstützt GLM-OCR?
A: GLM-OCR unterstützt PDF und JPG/PNG, Bild ≤ 10 MB, PDF ≤ 50 MB, bis zu 100 Seiten.
F: Welche Formen der GLM-OCR-Ausgabeergebnisse gibt es?
A: GLM-OCR kann Markdown-Textresultate ausgeben und strukturierte Informationen zum Layout zurückgeben.
F: Bietet GLM-OCR ein Online-Erlebnis und eine API?
A: Z.ai stellt API-Schnittstellenbeschreibungen auf der Online-Erfahrungsseite und in der Entwicklerdokumentation bereit.