1. Zusammenfassung
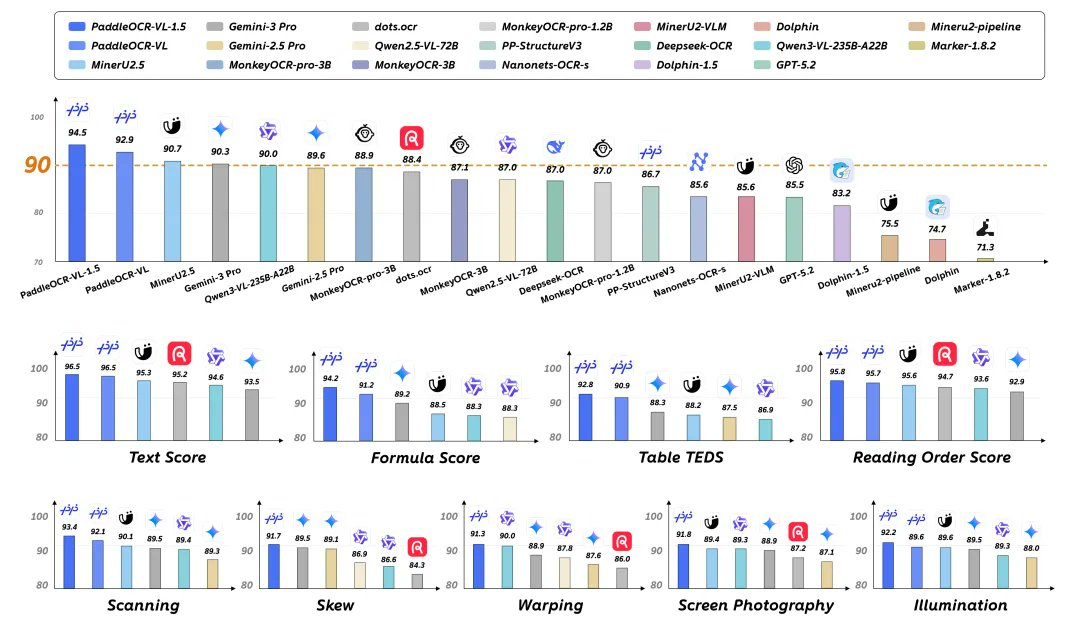
PaddleOCR-VL-1.5 ist ein quelloffenes 0,9B parametrisches Dokument-Multimodalmodell von PaddlePaddlePaddle, das integrierte Funktionen von Layoutpositionierung, Lesereihenfolge bis hin zu strukturierter Analyse wie Text/Tabelle/Formel usw. für reale Erfassungsszenarien wie "Biegen, Verzerrung, Neigung, Bildschirmfotografie und komplexe Beleuchtung" bietet. Die offiziellen öffentlichen Ergebnisse zeigen, dass es eine hohe Genauigkeit auf OmniDocBench v1.5 und Real5-OmniDocBench erreicht, was sich für das Verständnis von Dokumenten und die hochwertige Datenextraktion eignet.
2. Kernmerkmale
- Polygon-/unregelmäßige Flächenpositionierung: Mehrpunktpolygone werden anstelle starrer rechteckiger Boxen verwendet, die besser zu den Grenzen von Text und Elementen unter gekrümmter und perspektivischer Verzerrung passen.
- Siegel- und Signaturerkennung: Die Erkennungsfähigkeit für "Siegel/offizielles Siegel"-Elemente wurde hinzugefügt, was sich für die strukturierte Extraktion von Regierungs- und Unternehmensmaterialien sowie für Compliance-Szenarien eignet.
- Spread-Logik und globale Semantik: Unterstützen Sie das Verständnis auf "gesamter Dokumentenebene" wie das Zusammenführen von Spread-Tabellen sowie Titel- und Hierarchie-Assoziation, was die semantische Wiederherstellung langer Dokumente fördert.
- Multitask-Parsing: Text, Tabellen, Formeln, Diagramme und andere Elemente abdecken und End-to-End-Dokumentenparsing-Ausgaben (wie Markdown/JSON) bereitstellen.
- Leichtgewicht und hoher Durchsatz: 0,9 B-Parameter sind für kostenkontrollierte Bereitstellung praktisch; Das offizielle Material liefert End-to-End-Durchsatzdaten auf dem A100 für die Batch-Dokumentenverarbeitung.
- Mehrsprachig: Offizielle Materialien bieten eine umfassende mehrsprachige Abdeckung, einschließlich Tibetisch, Bengalisch und anderer Nebensprachen.
3. Installation
- Online-Erlebnis: Verwenden Sie direkt die ModelScope Online Demo, um Bilder oder PDFs hochzuladen und so schnell den Analyseeffekt von Szenen wie Biegung und Verzerrung, Bildschirmfotografie usw. zu überprüfen.
- Lokale Bereitstellung: Klonen Sie das PaddleOCR-Repository, installieren Sie Abhängigkeiten und modellieren Sie Ressourcen gemäß offizieller Dokumentation und priorisieren Sie die Nutzung von Docker, um Umweltunterschiede zu verringern.
- Inferenzbeschleunigung: Wenn hoher Durchsatz erforderlich ist, verwenden Sie Inferenz-Backends wie FastDeploy für dienstorientierte Bereitstellung und Batch-Verarbeitungsbeschleunigung, kombiniert mit Batch-Warteschlange und Nebenläufigkeitsparameteroptimierung.
4. Typische Anwendungsfälle
- Strukturkomplexe Scans: Verträge, Rechnungen, Papiere, Berichte usw. wandeln Bilder/PDFs in brauchbare strukturierte Markdown/JSON um.
- Restaurierung von Tabellen- und Inhaltsverzeichnis: Automatische Zusammenführung und Organisation der Tabelle auf Titelebene, um die Lesbarkeit und Abrufbarkeit langer Dokumente zu verbessern.
- Siegelelement-Extraktion: Entfernen Sie den Siegelbereich und Schlüsselinformationen in der Materialverifikations- und Risikokontrollarchivierung und verknüpfen Sie dies mit den Regeln/manuellen Überprüfungen.
- Dokument-RAG-Datenpipeline: Beibehaltung von Absätzen, Tabellen, Seitenzahlen und Elementkoordinaten, um das Abruf, die Zitationsposition und die Rückverfolgbarkeit der Antworten zu verbessern.
5. Ökologie und konkurrierende Produkte
- Ökologie: PaddleOCR bietet eine vollständige Toolchain von Dokumentrendering, Layoutanalyse bis hin zu strukturierter Ausgabe, was die Implementierung von Batch-Verarbeitung und Online-Diensten erleichtert.
- Konkurrierende Produkte: Allgemeine multimodale große Modelle und traditionelle OCR-/Dokumentparsing-Lösungen haben ihre eigenen Vorteile; PaddleOCR-VL-1.5 verfügt über überlagertes Multitasking mit "True Distortion Document Resolution" und kleineren Parametern. Die Vor- und Nachteile verschiedener Schemata hängen von den Datenverteilungs- und Auswertungseinstellungen ab, und es wird empfohlen, vor der Auswahl eigene Stichproben für Regressionstests zu verwenden.
6. Einschränkungen und Vorsichtsmaßnahmen
- Es besteht das Risiko einer Fehlzusammenführung zwischen Spannzusammenlegung und hierarchischer Inferenz: Für Dokumente mit extrem unregelmäßigem Layout und starker Beeinflussung von Kopf- und Fußzeilen sind Regelverifikation und Stichprobenprüfung erforderlich.
- Siegelerkennung hat starke geschäftliche Merkmale: Die Siegelstile unterscheiden sich stark zwischen Regionen/Einheiten, und es wird empfohlen, Domänendaten und Schwellenwerte zu ergänzen.
- Durchsatz und Kosten hängen von Rendering- und Inferenzverknüpfungen ab: PDF-Rendering-DPI, Chargengröße, Nebenläufigkeit und Backend-Implementierung beeinflussen Geschwindigkeit und Kosten erheblich.
- Öffentlichkeitsarbeit und Vergleich müssen sorgfältig interpretiert werden: Wenn Sie das Vergleichsergebnis mit einigen allgemeinen geschlossenen Quellmodellen sehen, sollten Sie auf die Konsistenz des Bewertungssets, der Prompt-Wörter und der Eingabeverarbeitung achten.
7. Projektadresse
https://github.com/PaddlePaddle/PaddleOCR
8. Häufig gestellte Fragen
F: Ist der PaddleOCR-VL-1.5 geeignet, um Dokumente OCR zu biegen und zu verdrehen?
A: Die offizielle Positionierung dient dem Scannen von Verzerrungen, Perspektivverdrehungen und Bildschirmkameras und bietet unregelmäßige Flächenpositionierung sowie End-to-End-Auflösungen; Es wird empfohlen, Ihre echte Entnahme zur Verifizierung zu verwenden.
F: Wie baue ich mit PaddleOCR-VL-1.5 ein hochpräzises Dokument-RAG?
A: Priorisieren Sie die Ausgabe strukturierter Ergebnisse (wie Markdown/JSON), behalten Sie die Titelebene, die Tabellenstruktur, die Lesereihenfolge, die Seitenzahl und die Koordinaten bei. Klicken Sie dann auf den "Absatz-/Tabellenblock", um sie in Lagerhäuser aufzuteilen und nachverfolgbare Referenzen zu erstellen.
F: Was soll ich tun, wenn der Zusammenführungseffekt der Spread-Tabellen instabil ist?
A: In der Nachbearbeitungsphase werden Konsistenzprüfungen hinzugefügt (Anzahl der Spalten/Header-Ähnlichkeit/Seitennummer-Naht) und manuell überprüft oder auf "Parse pro Seite" für Stichproben mit niedriger Konfidenz zurückgegriffen.
F: Was soll ich tun, wenn der Durchsatz nicht den offiziellen Daten entspricht?
A: Überprüfen Sie PDF-Renderzeit, Eingabeauflösung, Batch und Nebenläufigkeit, GPU-Auslastung sowie ob das offiziell empfohlene Inferenz-Backend und die Parameter verwendet werden. Jede Verbindung im End-to-End-Link wird zu einem Engpass.
F: Unterstützen Sie Tibetisch, Bengalisch und andere Sprachen?
A: Offizielle Quellen bieten mehrsprachige Berichterstattung und umfassen Tibetisch, Bengalisch usw.; Vor dem Start wird weiterhin empfohlen, eine spezielle Probenahme durchzuführen und die Zielsprache zu akzeptieren.