1. Zusammenfassung
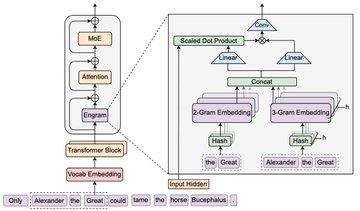
Engram ist ein Open-Source-"Conditional Memory"-Modul von DeepSeek, und die Kernidee ist es, dem Transformer einen erweiterbaren Form-Nachschlagsspeicher-Primitiv hinzuzufügen: Ein Teil des statischeren Musters/Wissens wird in Form einer N-Gramm-Speichertabelle gespeichert, während der Inferenz in etwa O(1)-Form abgerufen und mit dem aktuellen versteckten Zustand verschmolzen. Die Schlussfolgerung des offiziellen Repositoriums ist, dass Engram-27B unter den Einschränkungen gleicher Parameter und gleicher Rechenleistung stabile Erträge im Vergleich zum MoE-Baseline bei Aufgaben wie Wissen, Argumentation, Code und Mathematik bietet. Und die Mechanismusanalyse zeigt, dass sie die Belastung durch die "Rekonstruktion" des statischen Modells in der frühen Schicht verringern kann, sodass die effektive Tiefe für komplexere Schlussberechnungen erhalten bleibt.
2. Kernmerkmale
1. O(1) Gedächtnis der Formform, der Bedingungen,
Durch deterministische Adressierung und Abruf statischer N-Gramm-Speicher wird die "Wissenssuche" teilweise von dichter neuronaler Berechnung getrennt, wodurch die Besetzung des Rechenpfads reduziert wird.
2. "Spärliche neue Achse" ergänzend zum MoE
MoE erweitert die Kapazität durch bedingte Berechnungen, und Engram erweitert die Kapazität durch bedingten Speicher: Einer wird "berechnet" und der andere "geprüft", was effektiver unter denselben FLOPs nach der Kombination zugeordnet werden kann.
3. Das U-förmige Maßstabsgesetz wird für die Kapazitätszuweisung verwendet
Der offizielle Kompromiss zwischen "Computational Capacity (MoE) und Static Memory Capacity (Engram)" wird genannt und weist darauf hin, dass es ein U-förmiges Skalierungsgesetz gibt, das technische Abwägungen leiten kann.
4. Die Mechanismuserklärung ist näher an der ingenieurtechnischen Intuition
Das Repository erwähnt ausdrücklich, dass Engram möglicherweise die Notwendigkeit eliminieren könnte, dass frühe Schichten statische Muster wiederholt rekonstruieren müssen, und die Anzahl der Schichten und Darstellungsmöglichkeiten den späteren, kritischeren Inferenzprozessen überlassen werden kann, was als "effektivere Vertiefung für Inferenz" verstanden werden kann.
5. Systemeffizienz und Landbarkeit
Deterministische Adressierung wird verwendet, um hyperskalierte eingebettete Tabellen auf den Host-Speicher zu entlasten, und der erhöhte Inferenz-Overhead wird so kontrollierbar wie möglich gehalten.
3. Installation
1. Bereite die Umgebung vor
Python 3.8+, eine isolierte Umgebung (venv/conda), wird empfohlen.
2. Installationsabhängigkeiten
Schnellstart nach Repository: Installiere Abhängigkeiten wie Torch, Numpy, Transformers, Sympy usw.
3. Durchführung der Demonstration
Das Repository bietet engram_demo_v1.py zur Demonstration der Kerndatenströme von Engram; Diese Version simuliert einige Standardkomponenten (z. B. Attention/MoE usw.) und hebt hervor, wie Engram-Module funktionieren.
4. Typische Anwendungsfälle
1. Wissensintensive Frage-und-Antwort-Diskussion und faktisches Erinnern
Wenn die Aufgabe stärker auf den "stabilen Wissens-/festen Ausdrucksmodus" angewiesen ist, kann der Nachschlagespeicher die wiederholende Musterrekonstruktion des Modells in den ersten Schichten reduzieren.
2. Wiederverwendung stabiler Fragmente im langen Kontext
Statischer Speicher schlägt für wiederkehrende kurze Fragmente (feste Phrasen, Codevorlagen, gängige Formate) an, um ungültige Berechnungen in langen Kontexten zu reduzieren.
3. Vorlagenstruktur des Codes und mathematische Szenarien
Bei Aufgaben mit mehr "gemeinsamen Ableitungsroutinen/Codeskeletten" werden Speicherkanäle verwendet, um statischere Strukturen zu erstellen, während Rechenkanäle sich auf Kombination und Schlussfolgerung konzentrieren.
4. Kosteneffiziente Expansion in Kombination mit MoE
Unter der Annahme, dass die Gesamtparameter und die gesamten FLOPs begrenzt sind, wird der "Teil der Kapazität in die statische Speichertabelle gelegt" im Austausch für eine höhere effektive Kapazitätsdichte.
5. Ökologie und konkurrierende Produkte
1. Ökologischer Status
Derzeit basiert das offizielle Repository hauptsächlich auf Papers + Strukturdiagrammen + experimentellen Diagrammen + Demos, was sich eignet, um die neue Komponente des "bedingten Speichers" schnell zu verstehen und den Kombinationsraum mit dem bestehenden MoE-Stack zu evaluieren.
2. Konkurrenzprodukte und angrenzende Richtungen
Benachbarte Ideen umfassen typischerweise: RAG (External Retrieval Enhancement), kNN-LM/Nearest Neighbor Retrieval, Traditional N-Gram/Caching und verschiedene Sparse-Attention/Sparse-Routing-Architekturen. Der Unterschied von Engram besteht darin, dass es eine "trainierbare statische Speichertabelle" als internes Primitiv des Modells verwendet und die Arbeitsteilung und Skalierung mit MoE betont. Der tatsächliche Effekt muss noch in Kombination mit spezifischer Datenverteilung, Trainingsrezept und Einsatzbedingungen überprüft werden.
6. Einschränkungen und Vorsichtsmaßnahmen
1. Details und Reproduktionsqualität des Papiers
Das Repository liefert wichtige Schlussfolgerungen und Demos, aber die Details zu groß angelegten Schulungen, der Umsetzung und vollständigen Ablation sollten weiterhin auf dem Artikel basieren.
2. Kompromisse zwischen Speicher und Bereitstellung
Das Auslasten riesiger Speichertabellen auf den Host-Speicher reduziert den Speicherdruck, bringt aber neue Einschränkungen hinsichtlich Bandbreite, Latenz und technischer Komplexität mit sich.
3. Die Anwendbarkeit hängt von der Art der Aufgabe ab
Wenn der Hauptengpass der Aufgabe "dynamisches Schließen/kombinatorische Verallgemeinerung" statt "statischer Modus/Wissenswiederverwendung" ist, sind die Vorteile möglicherweise nicht so offensichtlich wie bei wissensintensiven Aufgaben.
4. Integrationskosten mit dem bestehenden Schulungssystem
Um neue Module mit bestehenden MoE/Attention-Implementierungen und parallelen Strategien zu verbinden, müssen Sie Trainingsstabilität, Durchsatz und Monitoring-Kennzahlen (wie Trefferrate, Tabellenkapazitätsauslastung usw.) bewerten.
7. Projektadresse
https://github.com/deepseek-ai/Engram
8. Häufig gestellte Fragen
F: Was sind die zentralen Schlüsselwörter von Engram und welche Probleme löst es?
A: Die Schlüsselwörter sind Conditional Memory, Scalable Lookup, O(1)-Lookup-Speicher und N-Gramm-Speicher. Es versucht, dem Transformer die Möglichkeit zu geben, "native Knowledge lookup" zu machen, um einige statische Muster/Wissen von intensiver Berechnung zu trennen.
F: Wie ist die Beziehung zwischen Engram und MoE?
A: MoE erweitert die Kapazität durch bedingte Berechnung, und Engram erweitert die Kapazität durch bedingten Speicher. Die beiden können sich ergänzen und eine Arbeitsteilung bilden: "Berechnung (Berechnung) + Überprüfung (Speicher)".
F: Was bedeutet die offizielle mechanistische Analyse mit "effektiver und tiefer"?
A: Die Repository-Sichtweise ist, dass Engram die Belastung für statische Muster in den frühen Schichten reduziert, wodurch die Netzwerktiefe stärker auf die anschließende komplexe Inferenz fokussiert wird, was wie "Tiefe für Schlüsselteile zu belassen".
F: Wie kann ich schnell überprüfen, wie Engram funktioniert?
A: Um die vom Lager bereitgestellten engram_demo_v1.py direkt zu betreiben, sollten Sie zunächst den Datenfluss und die Fusionsposition verstehen. Die Demo wird gängige Komponenten simulieren, um Engram hervorzuheben.
F: Ist Engram als Alternative zu RAG geeignet?
A: Es eignet sich eher als ergänzende Richtung: RAG steht für externe Dokumentenabrufung und -aktualisierung, und Engram ist eine interne statische Speicher-Primitive Sprache sowie die Arbeitsteilung im Rechnen/Gedächtnis. Die Substitution hängt davon ab, ob die Aufgabe externes aktualisiertes Wissen und eine steuerbare Abrufverbindung benötigt.



