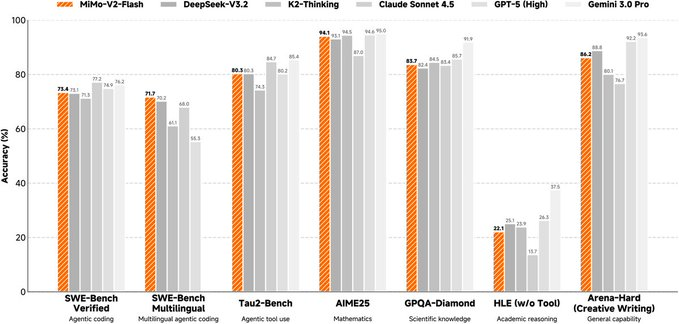
小米MiMo与小米大模型Core团队发布并开放MiMo-V2-Flash相关资源,定位为面向高速度推理与智能体工作流的基础语言模型,模型权重与推理部署资料同步提供给开发者与研究者使用。
该模型为Mixture-of-Experts(MoE)架构,总参数约309B、推理时激活约15B,并支持最高约256K上下文长度。其混合注意力设计将滑动窗口注意力与全局注意力按比例交织,并采用较小窗口以压缩KV缓存开销;同时引入轻量多Token预测(MTP)模块以提升解码输出速度,官方也额外提供多层MTP权重供社区研究。模型页面与仓库同时给出训练与后训练要点(含FP8混合精度与面向智能体的强化学习/蒸馏路线),并列出多项评测结果用于对比参考。
需要注意的是,此类超大规模MoE模型对算力与推理框架要求较高,评测成绩与实际业务效果可能受提示词、工具链、量化与推理并行策略影响;在商用与再分发前,也应核对模型页与代码仓库的具体许可条款与适用范围。
常见问题
Q:MiMo-V2-Flash是什么类型的模型?
A:MiMo-V2-Flash是小米MiMo团队发布的MoE基础语言模型,面向高速推理与智能体任务场景。
Q:MiMo-V2-Flash的参数规模与上下文长度是多少?
A:公开信息显示其总参数约309B、激活约15B,并支持最高约256K上下文长度。
Q:MiMo-V2-Flash的“混合注意力”和MTP主要解决什么问题?
A:混合注意力侧重降低长上下文推理的KV缓存成本,MTP侧重提升解码阶段的输出吞吐与速度。
Q:MiMo-V2-Flash的模型权重与技术报告在哪里获取?
A:模型权重可在Hugging Face获取,代码与技术报告在GitHub仓库提供,同时官网博客与LMSYS文章也整理了入口。
Q:MiMo-V2-Flash在落地部署时最容易踩的坑是什么?
A:常见问题包括显存/带宽不足、推理框架对MoE与MTP支持不完整、量化与并行配置不当导致速度或质量波动。