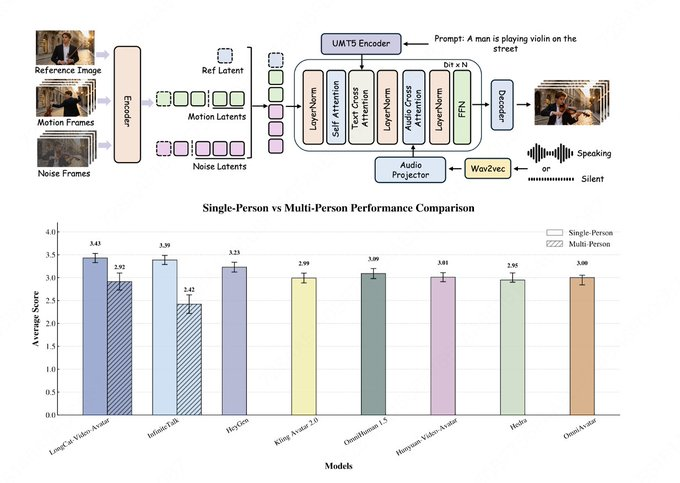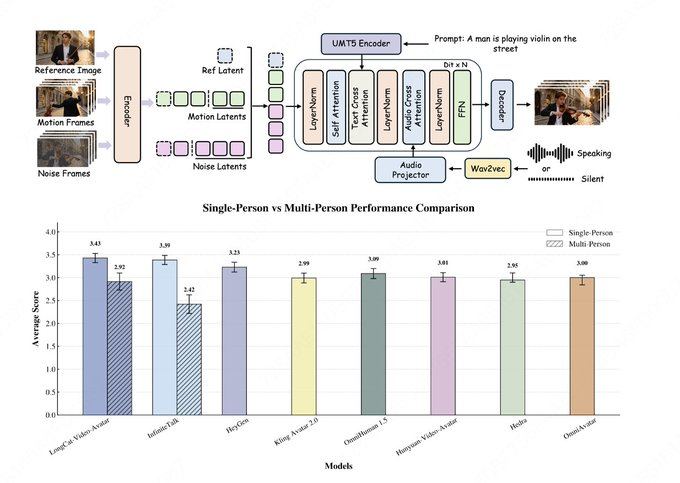
美团LongCat团队在LongCat-Video代码库更新中宣布发布LongCat-Video-Avatar,并同步上线项目页与Hugging Face权重。该模型定位为“音频驱动”的人物视频生成方案,基于LongCat-Video架构,支持Audio-Text-to-Video(AT2V)、Audio-Text-Image-to-Video(ATI2V)以及音频条件的视频续写,可覆盖单人、多人物与长时长内容生成。
公开材料显示,LongCat-Video-Avatar主打长序列稳定性与更自然的动态表现:通过Cross-Chunk Latent Stitching减少长视频生成中的退化与接缝问题,并用Reference Skip Attention在保持身份一致性的同时降低“硬复制”痕迹;同时提出解耦式引导策略,减少对语音信号的过度依赖,改善静音段过于僵硬的问题。团队在模型卡中引用EvalTalker作为人类评测基准并展示自然度与真实感对比,但外部榜单排名、参与者规模等细节在公开页面未完整披露,相关结论仍需以评测论文与可复现实验为准。
常见问题
Q:LongCat-Video-Avatar是什么模型?
A:LongCat-Video-Avatar是面向人物表演的音频驱动视频生成模型,强调长时序稳定性、口型同步与身份一致性。
Q:美团LongCat团队发布的LongCat-Video-Avatar支持哪些生成模式?
A:LongCat-Video-Avatar支持AT2V、ATI2V,以及音频条件的视频续写与长视频扩展。
Q:LongCat-Video-Avatar与InfiniteTalk的差异点是什么?
A:LongCat-Video-Avatar在介绍中强调更自然的动态与更稳的长序列表现,并用Reference Skip Attention降低参考图注入导致的“复制粘贴”伪影。
Q:开发者使用LongCat-Video-Avatar需要注意哪些风险?
A:开发者需要关注肖像与音频授权、合规与内容安全,并避免在未获许可情况下生成可被误用的仿真人物内容。