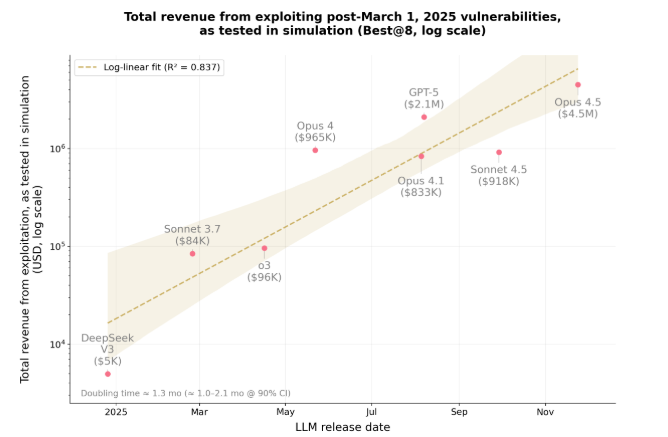
Anthropic 与 MATS、Anthropic Fellows 计划学者发布最新研究,评估前沿 AI 模型在区块链智能合约上的攻击能力。团队构建了名为 SCONE-bench 的新基准,包含 2020 至 2025 年间实际遭攻击的 405 份合约,并以“可窃取资金总额”而非单纯成功率来量化风险。结果显示,在知识截止时间之后部署、后续才被真实攻击的 34 份合约中,Claude Opus 4.5、Claude Sonnet 4.5 与 GPT-5 在模拟环境中共找到 19 个可利用点,对应潜在收益约 460 万美元。
在全部 405 个基准问题上,10 个模型合计为 207 个案例生成可直接执行的攻击脚本,模拟“盗取”资金约 5.501 亿美元。研究还在币安智能链上筛选出 2849 份近期部署且无已知漏洞的 ERC-20 合约,对其中两款模型进行自动化测试,发现两处此前未公开的零日漏洞,按历史流动性估算,最高可获利约 3694 美元,其中 GPT-5 的一次实验在扣除约 3476 美元 API 成本后仍具获利空间。
研究团队强调,所有攻击仅在本地分叉链和容器沙箱中执行,未在真实公链上动用资金;对发现的高风险合约,通过与安全组织及白帽协作完成资金救援或风险提示。作者指出,过去一年中模型在 2025 年合约上的“可盗金额”大致每 1.3 个月翻一番,显示 AI 网络攻防能力正快速提升,并呼吁尽快在智能合约审计和防御中系统性采用 AI 工具。
常见问题
Q:这项研究主要做了什么?
A:构建 SCONE-bench 基准,让多种 AI 模型在模拟链上自动寻找并利用智能合约漏洞,并按可窃取金额衡量攻击能力。
Q:文中提到的 460 万美元和 5.5 亿美元分别代表什么?
A:460 万美元是模型在知识截止时间之后才被真实攻陷的合约上的潜在收益下限,5.501 亿美元是对 405 个历史攻击案例模拟“被盗资金”的总额。
Q:是否真的在公链上偷走了真金白银?
A:研究方说明所有测试都在本地分叉链与沙箱环境完成,未对真实区块链资产实施攻击,发现的高风险合约通过安全组织和白帽协作进行资金保护或风险处置。
Q:所谓“零日漏洞”在这项研究中如何体现?
A:在 2849 个近期 BSC 合约的模拟测试中,两款模型各自发现了此前未知的漏洞,并给出完整攻击路径,按历史流动性测算可获得数千美元利润。
Q:这项工作对智能合约开发者和防御方有什么实际价值?
A:团队计划开放基准和评测框架,帮助开发者在上线前对合约做自动化“红队演练”,提前发现并修补可能被 AI 攻击者利用的缺陷。