两个月前,DeepSeek 发布实验性模型 V3.2-Exp,并通过用户回访确认其在各类场景中不逊于 V3.1-Terminus,验证了 DSA 稀疏注意力机制的有效性。最新发布的正式版 DeepSeek-V3.2 与 DeepSeek-V3.2-Speciale 现已亮相,其中 V3.2 已在官网网页端、App 与 API 全面替换 V3.2-Exp,成为默认服务模型;Speciale 版本则以临时 API 服务形式开放,用于社区评测与研究。
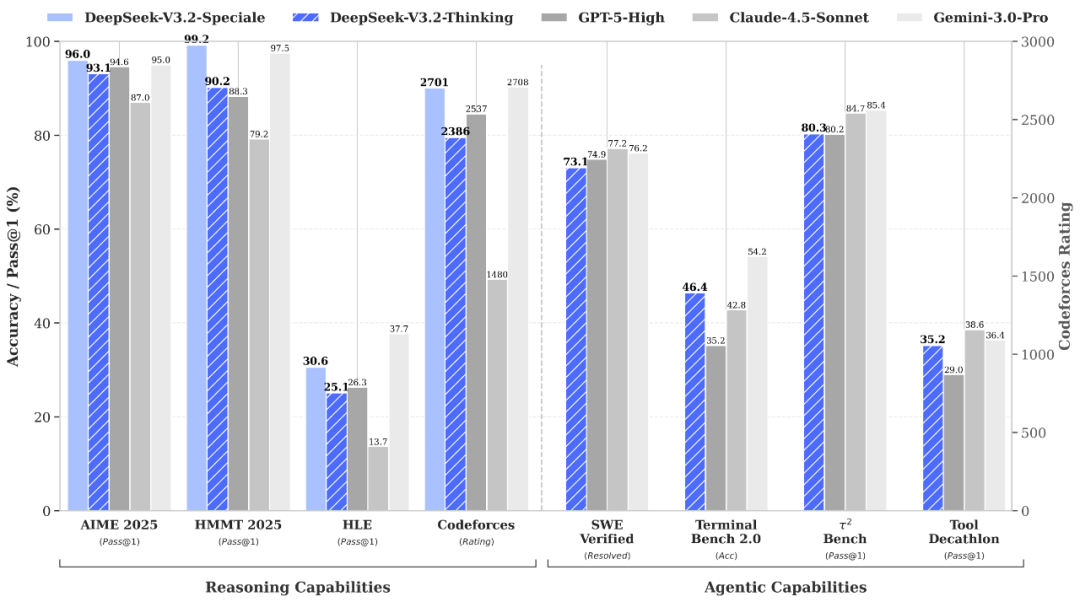
官方称,V3.2 的目标是在推理能力与输出长度之间取得平衡,适合问答和通用 Agent 等日常场景,在公开推理 Benchmark 上达到 GPT-5 水平,仅略低于 Gemini-3.0-Pro,且相较 Kimi-K2-Thinking 在输出长度和计算开销上更为节制。V3.2-Speciale 则在长思考能力上大幅增强,并融合 DeepSeek-Math-V2 的定理证明能力,在 IMO、CMO、ICPC 世界总决赛及 IOI 2025 中取得金牌成绩,其中 ICPC、IOI 表现分别接近人类选手第二名与第十名。该模型专攻复杂推理任务,Token 消耗显著更高,目前仅支持思考模式对话,不开放工具调用,最大输出长度为 128K。
在智能体应用方面,DeepSeek-V3.2 成为首个将“思考”直接融入工具调用的模型,既可在思考模式下多轮“思考+调用工具”,也支持非思考模式调用。官方通过合成 1800 余个环境、8.5 万条复杂指令构建大规模 Agent 训练数据,使模型在多种智能体评测中达到当前开源模型的领先水平。V3.2-Speciale 则通过临时端点 base_url 配置访问,预计服务至 2025 年12月15日,北京时间 23:59 截止。
常见问题
Q:DeepSeek-V3.2 和 V3.2-Speciale 的定位有什么不同?
A:V3.2 面向日常问答和通用 Agent,强调推理与成本平衡;V3.2-Speciale 则追求极限推理能力,专注高难数学与编程任务。
Q:现在在网页端和 App 上调用到的是哪个模型?
A:DeepSeek 已将网页端、App 与标准 API 默认模型统一升级为正式版 DeepSeek-V3.2,不再使用 V3.2-Exp。
Q:V3.2-Speciale 如何访问,有哪些限制?
A:需在 API 中设置特定 base_url 才能调用,该版本仅支持思考模式对话、不支持工具调用,最大输出长度为 128K,服务开放到 2025 年12月15日。
Q:“思考模式下的工具调用”具体指什么?
A:指 V3.2 可以在推理过程中多次插入工具调用,再结合工具返回结果继续思考,适合复杂、多步骤的 Agent 任务场景。
Q:两个模型都已经开源了吗?
A:官方已在 HuggingFace 和 ModelScope 发布 V3.2 与 V3.2-Speciale 的开源权重,供社区下载使用,同时配套技术报告与思考模式 API 文档。


