一、摘要
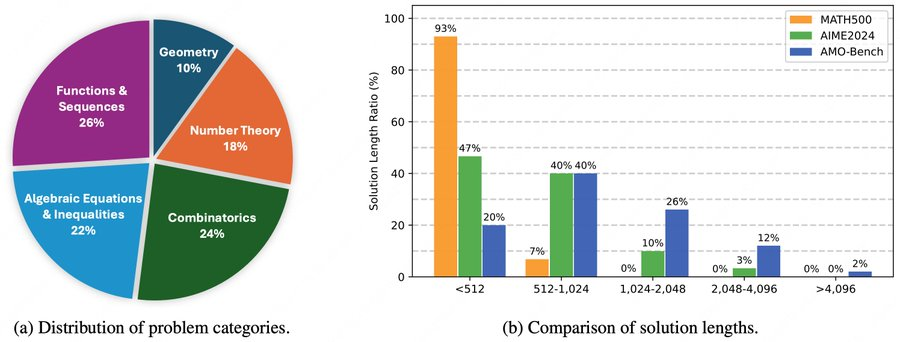
AMO-Bench 是美团 LongCat 团队推出的高级数学推理基准,聚焦于国际数学奥林匹克(IMO)级别乃至更高难度的竞赛题。基准由 50 道全新人类专家设计题目构成,通过自动评分与人工链式思维(CoT)标注,系统评测大模型在高难度数理推理上的真实上限。当前公开结果显示,Kimi-k2-Thinking 得分约 56%,GPT-5-thinking(high)与 Qwen3-235B-Thinking 紧随其后,大部分模型仍低于 40%。
二、核心特性
1、原创 IMO 级难题集:50 道题均由人类专家设计与交叉验证,明确标定为至少 IMO 难度,有助于避免训练语料记忆带来的“刷榜”。
2、高精度自动评分:采用规则 + 模型混合的评分算法,对数值答案、表达式等进行鲁棒比对,官方宣称整体评分准确率可达 99.2%。
3、人类标注 CoT:每道题配有人类链式推理过程,方便分析模型错误模式,也可作为后续监督微调或强化学习的参考信号。
4、专注推理而非格式:题目仅要求最终答案,无需完整证明,大幅降低人工评卷成本,支持大规模可复现评测。
三、安装
1、从 Hugging Face 数据集页面下载 AMO-Bench(或使用 datasets 等工具拉取),解压到本地目录。
2、克隆 GitHub 仓库,按照 README 安装 Python 依赖与评测脚本。
3、在配置文件中指定模型调用方式(本地推理或云端 API)、并设定输出与日志路径。
4、运行官方示例脚本,先在少量样例上验证评测与自动打分流程,再进行全量评测。
四、典型用例
1、大模型基准评测:将 AMO-Bench 与 GSM8K、MATH、AIME 等数据集组合,用于区分高端模型在“极限难题”上的差异。
2、推理策略对比:对比直接回答、逐步思考(CoT)、反思重试等不同推理模式在同一题集上的表现。
3、训练与微调信号:将题目与人类 CoT 作为高质量监督数据,用于强化模型的数学推理链条。
4、研究 token 开销与 compute scaling:在固定题集上分析不同模型及解题策略的输出长度与算力消耗。
五、生态与竞品
1、生态:项目提供数据集、自动评分代码、示例脚本与公开结果,可方便接入现有的大模型评测流水线与 LongCat 生态。
2、与传统基准对比:相较于 GSM8K、MATH、AIME24/25 等已经出现“成绩饱和”的基准,AMO-Bench 将难度抬升到 IMO 区间;与强调证明质量的 IMO-ProofBench 等基准不同,它更关注“高难推理 + 自动评测”的结合。
六、局限与注意事项
1、题目数量仅 50 道,整体统计置信度有限,更适合用作高难度压力测试和排行榜,而非覆盖全面能力的通用基准。
2、题目集中于高中奥数风格,对开放式推理、跨学科综合能力的覆盖有限。
3、自动评分虽经精心设计,极端或非常规输出格式仍可能出现误判,关键模型评测结果建议抽样人工复核。
4、在研究或产品中使用前,应核对仓库与数据集的 License 条款,确认是否允许商用与再分发。
七、项目地址
https://github.com/meituan-longcat/AMO-Bench
八、常见问题
Q:AMO-Bench 数据集如何获取与加载?
A:可以直接从 Hugging Face 数据集页面或官方项目页提供的链接下载,本地解压后通过 Python(如 datasets、自定义脚本)按题目与答案字段进行加载。
Q:AMO-Bench 更适合评测哪些类型的大模型?
A:主要面向具备较强数学与符号推理能力的通用大模型,尤其是提供“Thinking/Reasoning/CoT”模式的版本;对中小模型来说,该基准往往过于困难,得分可能极低。
Q:如何在本地复现实验或接入自己的模型?
A:按照 GitHub 仓库说明安装依赖,配置模型推理接口(如本地推理服务或云端 API),再调用官方评测脚本统一生成答案文件并自动打分,即可得到与论文同分布的指标。
Q:AMO-Bench 是否适合直接用作训练集?
A:可以在研究场景中用于微调或强化学习,但由于题目数量有限,更推荐将其保留为验证集或测试集,仅在更大规模数学语料上进行训练,以避免过拟合该基准。



