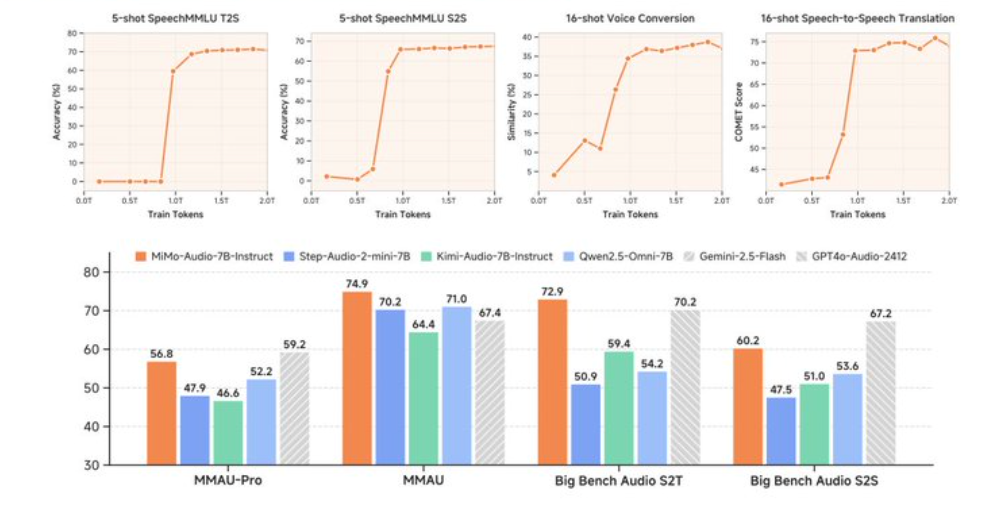
开源音频大模型 MiMo-Audio 宣称在百百万小时级别的预训练后,实现跨任务少样本泛化,并在 MMSU、MMAU、MMAR、MMAU-Pro 等基准上取得领先。对内容审核、智能客服、播客检索、会议纪要、语音体感游戏等场景,MiMo-Audio 的通用音频理解与推理能力值得立刻关注与验证。
一、这次“开源+音频通用智能”到底新在哪
1、Scaling 路线:100M+ 小时预训练
关键词:MiMo-Audio、预训练、Few-shot。核心在于把大规模自监督学习迁移到音频语言模型,通过“音频→文本”对齐,少样本即可适配说话人识别、环境声理解、音乐结构分析等多类任务。
2、任务覆盖:从理解到对话与合成
关键词:MiMo-Audio-7B-Instruct、指令微调。指令后模型不仅做音频问答,还能进行多轮对话、事件抽取、节拍与音色要素描述,形成“听懂→说清”的闭环。
(1)评测信号与对比口径
关键词:MMSU、MMAU、MMAR、MMAU-Pro。基准更强调跨领域与复杂推理,少样本场景下更能反映通用能力。对比时务必标注开源/闭源、上下文长度、提示长度与是否允许外部工具。
二、如何快速试用与落地
1、最低可行验证方案(POC)
关键词:MiMo-Audio、HF Space、体验闭环。用官方交互空间验证三步:设定任务清单(如说话人数、关键词、场景分类)、准备 10-20 条带标注音频、用同一提示模板做 A/B 对比并统计准确率与延迟。
2、工程化要点与成本预估
关键词:7B、推理加速、量化。7B 体量适合单机部署,可结合 4/8bit 量化与流式前端;服务器侧建议启用批处理与缓存。对短音频延迟目标:首响应 <800ms,整段完成 <2-3s。
(1)安全与合规清单
关键词:内容安全、隐私合规。需加入未成年语音保护、地域敏感词包、环境声包含个人隐私的脱敏策略;对医疗、司法、金融音频,增加人工抽检与审计日志。
三、用它解决哪些“真问题”
1、客服与质检
关键词:音频理解、少样本。快速抽取违规承诺、价格口径、情绪激烈通话;少样本即可迁移到新产品线。
2、媒体与创作
关键词:播客检索、采访摘要。对长音频生成带时间戳的大纲、人物卡与金句片段,辅助剪辑与二次分发。
(1)行业级复杂场景
关键词:安防与工业声学。对异常机械声、爆管声、玻璃破裂声进行多步推理并匹配告警级别。
常见问题解答(Q&A)
Q:MiMo-Audio 与传统 ASR+NLP 拼接方案相比有什么优势?
A:在少样本泛化与复杂推理上,MiMo-Audio 通过统一模型完成“听懂+推理”,减少级联误差,尤其在多说话人与环境声任务更稳。
Q:MiMo-Audio-7B-Instruct 是否适合私有化部署?
A:7B 体量可在单机或小集群落地,配合量化、KV Cache 与批处理,能满足大多数企业的吞吐与延迟目标。
Q:如何客观验证“超越闭源模型”的说法?
A:基于 MMSU、MMAU、MMAR、MMAU-Pro 复现实验,固定评测脚本、温度、上下文长度与提示模板,记录少样本 K 值与统计显著性。
Q:对中文真实业务是否友好?
A:可准备 3-5 小时行业语料做少样本自适应,覆盖口音、方言、域内术语;若目标是分角色摘要,需额外提供角色锚点样例以提升稳定性。