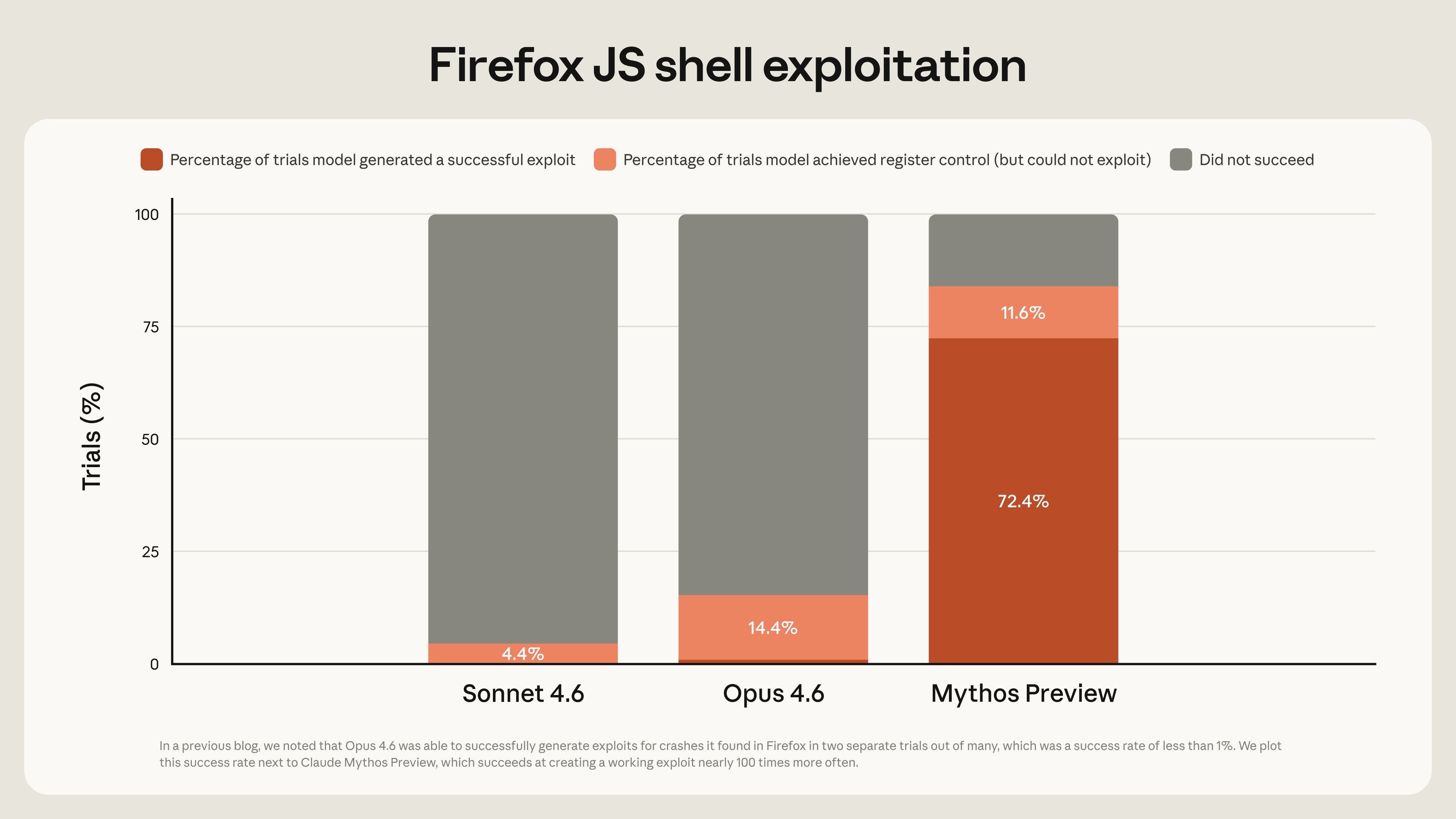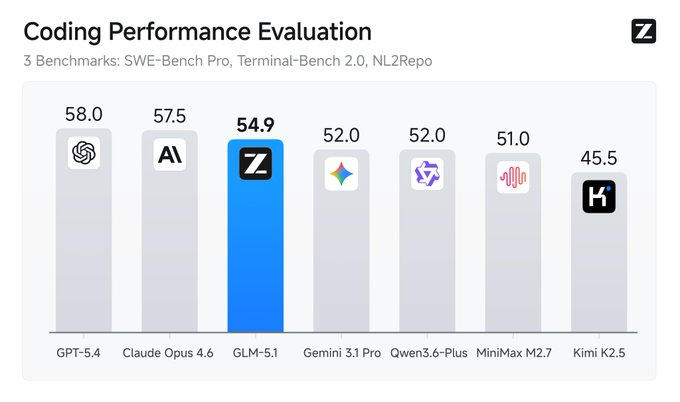
GLM-5.1 正式发布,Z.ai 将其定义为面向 agentic engineering 的新一代开源旗舰。官方资料显示,这款模型主打代码、工具调用与长时自主执行,在 SWE-Bench Pro、NL2Repo 和 Terminal-Bench 2.0 等任务上给出一组靠前成绩,同时把单任务连续自主工作时间拉到 8 小时。
开源代码模型转向工程任务
从产品定位看,Z.ai 这次并没有把重心放在通用聊天,而是把 GLM-5.1 明确推向代码代理与工程任务。官方给出的卖点集中在仓库生成、终端操作和真实软件修复,这也说明开源模型竞争正在从“会不会写代码”转向“能不能完成真实工程交付”。
围绕 SWE-Bench Pro、NL2Repo 和 Terminal-Bench 2.0 的成绩,GLM-5.1 想争夺的不是一次单点跑分优势,而是在代码模型市场里建立“可执行”的产品认知。对开发者来说,模型能否处理复杂仓库、完成多步操作,比单轮回答是否流畅更重要。
8小时长时执行是核心卖点
比榜单更值得看的是长时任务能力。Z.ai 明确强调,GLM-5.1 可在单一任务上连续自主运行 8 小时,并在过程中不断调整策略,完成数百轮迭代和数千次工具调用。这种能力指向的不是简单问答,而是更接近真实软件工程的连续工作流。
过去行业更关注模型单轮输出是否足够聪明,现在越来越看重它能否在复杂目标下持续推进任务。计划、执行、测试、修复能否连成闭环,决定了代码 Agent 能不能真正进入开发流程,这也是 GLM-5.1 试图放大的差异点。
权重、API与产品化同步推进
这次发布并不只是放出一组 benchmark。GLM-5.1 已同步开放权重,也提供 API 接入,并计划在未来几天上线 chat.z.ai。对 Z.ai 来说,这种同时铺开开源、开发接口和产品入口的方式,明显是在争取更快的开发者采用速度。
从行业竞争看,开源模型的关键已经不只是“有没有开放”,而是能否更快进入真实使用场景。GLM-5.1 这次强调代码能力、长时自主执行和多入口交付,说明 Z.ai 想切入的不是通用模型热度,而是更具体的 AI 编程市场。
GLM-5.1 这次最值得看的,不是又多了一款开源模型,而是 Z.ai 正把开源代码模型推向“长时自治代理”。接下来真正决定它位置的,不会只是一轮榜单成绩,而是开发者是否愿意把更完整的工程任务交给它。