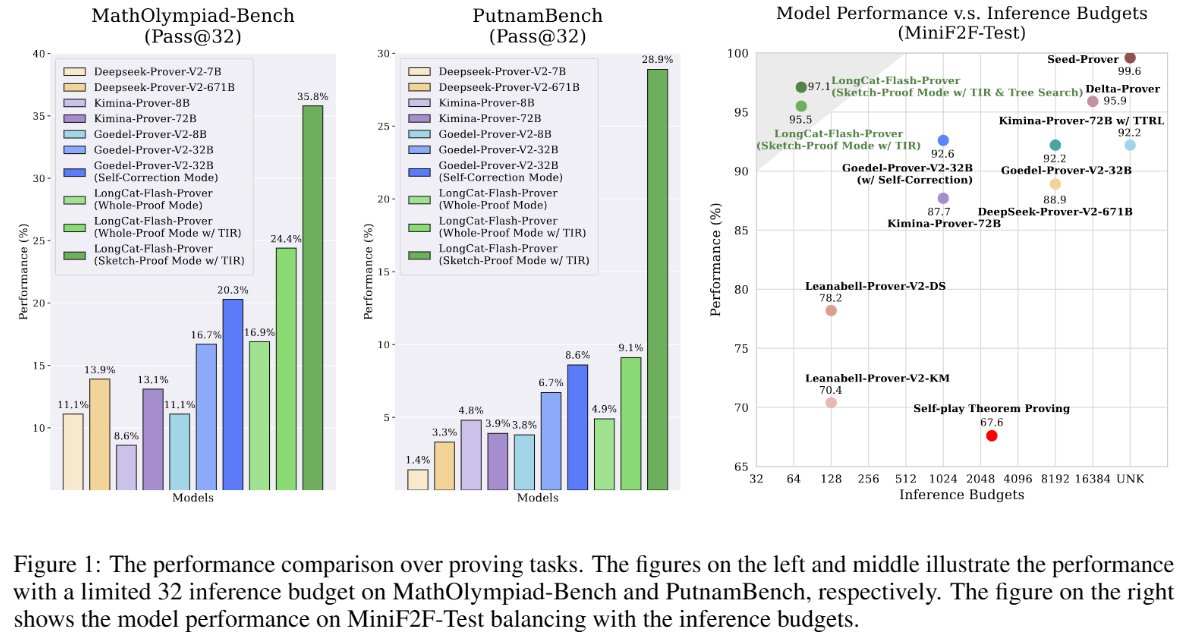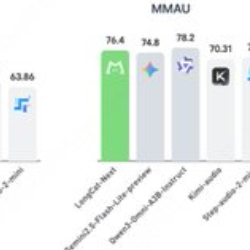
一、摘要
LongCat-Next 是美团 LongCat 团队开源的离散原生自回归多模态模型,目标是在同一框架中统一处理文本、视觉与音频。项目采用 MoE 架构,总参数约 68.5B、激活参数约 3B,强调“看、画、说”在单一离散 token 空间内协同完成,面向工业级多模态场景提供理解、生成和交互能力。
二、核心特性
1、DiNA 范式:将 Next-Token Prediction 从语言扩展到原生多模态,把文本、图像、音频统一到共享离散 token 空间。
2、dNaViT:支持任意分辨率图像的离散编码与重建,兼顾视觉理解与视觉生成。
3、视觉理解:覆盖 OCR、图表理解、GUI 解析、文档分析等任务,并具备一定 STEM 推理能力。
4、视觉生成:支持高压缩比下的任意分辨率生成,在文本渲染场景具有较强竞争力。
5、语音能力:支持音频理解、低延迟语音交互与可定制语音克隆。
三、安装
1、从官方 GitHub 获取代码,并按仓库说明创建运行环境。
2、推荐环境包括 Python 3.10 及以上、Torch 2.6 及以上、Transformers 4.57.6 及以上、Accelerate 1.10.0 及以上。
3、安装 requirements 与补充依赖后,从 Hugging Face 加载 LongCat-Next 权重。
4、官方示例显示,基于 Transformers 的本地推理通常至少需要 3 张 80GB 显存 GPU。
四、典型用例
1、文档理解:发票、表格、报告、截图等内容的识别与解析。
2、界面分析:对软件界面、按钮布局、交互流程进行理解。
3、多模态问答:把文本、图像与音频作为统一输入进行综合推理。
4、图像生成:生成海报、带文字图片和多分辨率视觉内容。
5、语音交互:实现语音问答、语音转语音和定制化语音合成。
五、生态与竞品
1、生态方面,LongCat-Next 已提供 GitHub、Hugging Face、在线 Demo、博客介绍与技术报告入口。
2、与常见“视觉编码器或音频编码器外挂到 LLM”方案相比,LongCat-Next 更强调原生统一建模。
3、与单点最优的专用视觉模型、图像生成模型或语音模型相比,它的优势是统一框架与多任务覆盖,代价是部署复杂度更高。
六、局限与注意事项
1、部署门槛较高,对显存、带宽和整体算力要求明显。
2、视觉生成与语音克隆能力在实际应用中需要额外考虑安全、版权与合规问题。
3、离散视觉路线虽然在理解和生成统一上有特色,但具体效果仍应以目标业务实测为准。
4、作为新近开源项目,其接口、依赖和最佳实践仍可能继续变化。
七、项目地址
https://github.com/meituan-longcat/LongCat-Next
八、常见问题
Q: LongCat-Next 是什么?
A: LongCat-Next 是美团 LongCat 团队开源的离散原生自回归多模态模型,统一处理文本、图像和音频。
Q: LongCat-Next 的核心技术 DiNA 是什么?
A: DiNA 是一种把 Next-Token Prediction 扩展到原生多模态的建模范式,用共享离散 token 空间统一语言、视觉和音频。
Q: LongCat-Next 的 dNaViT 有什么作用?
A: dNaViT 是 LongCat-Next 的视觉离散化与重建模块,支持任意分辨率图像的理解与生成。
Q: LongCat-Next 适合哪些应用场景?
A: 它适合 OCR、图表理解、GUI 解析、文档分析、多模态问答、图像生成和语音交互等场景。
Q: LongCat-Next 本地部署的硬件要求高吗?
A: 是的,官方示例显示其部署对 GPU 显存要求较高,更适合高性能算力环境。