一、摘要
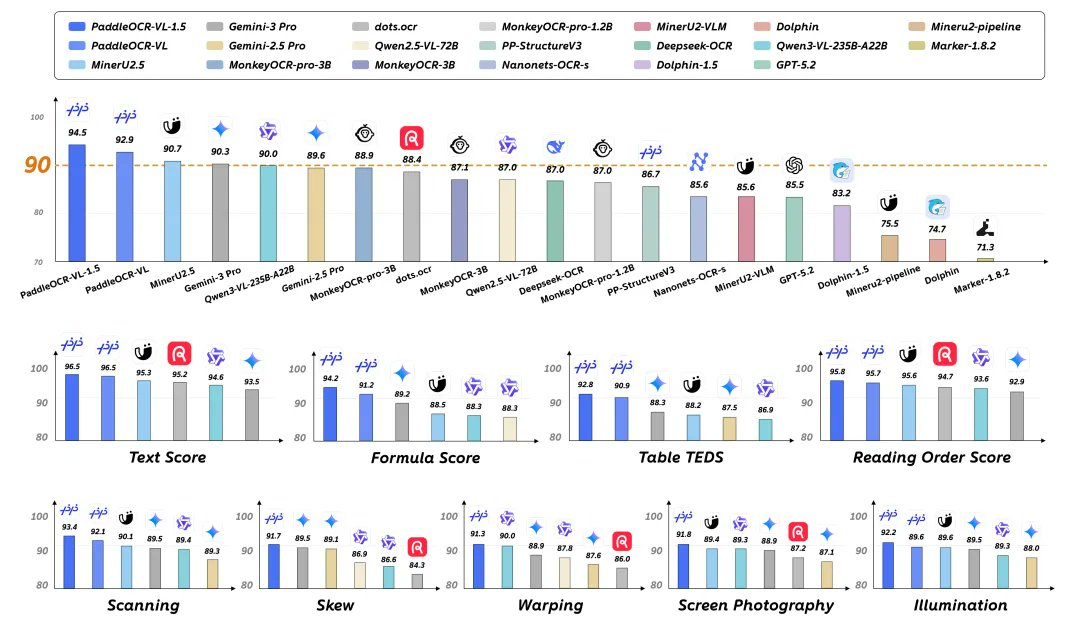
PaddleOCR-VL-1.5 是 PaddlePaddle 开源的 0.9B 参数文档多模态模型,面向“弯曲、扭曲、倾斜、屏摄、复杂光照”等真实采集场景,提供从版面定位、阅读顺序到文本/表格/公式等结构化解析的一体化能力。官方公开结果显示其在 OmniDocBench v1.5 与 Real5-OmniDocBench 上取得较高准确率,适合用于文档理解与高质量数据抽取。
二、核心特性
1、多边形/不规则区域定位:以多点多边形替代刚性矩形框,更贴合弯曲与透视畸变下的文本与元素边界。
2、印章与签章识别:新增面向“印章/公章”类要素的识别能力,适用于政企材料与合规场景的结构化抽取。
3、跨页逻辑与全局语义:支持跨页表格合并、标题与层级关联等“整份文档级”理解,有利于长文档语义还原。
4、多任务解析:覆盖文本、表格、公式、图表等要素,并提供端到端的文档解析输出(如 Markdown/JSON)。
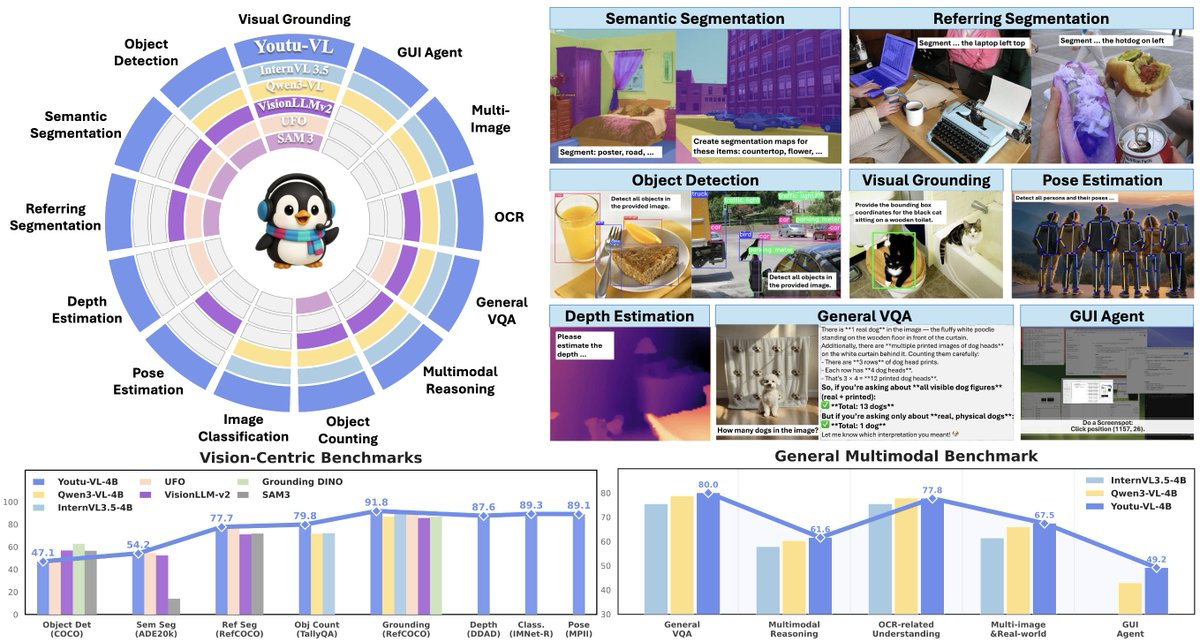
5、轻量与高吞吐:0.9B 参数便于成本可控部署;官方材料给出在 A100 上的端到端吞吐数据,适合批量文档处理。
6、多语种:官方资料给出较广的多语种覆盖,并包含藏文、孟加拉文等小语种支持。
三、安装
1、在线体验:直接使用 ModelScope Online Demo 上传图片或 PDF,快速验证弯曲扭曲、屏摄等场景的解析效果。
2、本地部署:克隆 PaddleOCR 仓库,按官方文档安装依赖与模型资源,优先使用 Docker 以减少环境差异。
3、推理加速:在需要高吞吐时,使用 FastDeploy 等推理后端进行服务化部署与批处理加速,并结合批量队列与并发参数调优。
四、典型用例
1、复杂扫描件结构化:合同、票据、论文、报表等,将图像/PDF 转为可用的结构化 Markdown/JSON。
2、跨页表格与目录还原:对跨页表格自动合并、标题层级整理,提升长文档可读性与可检索性。
3、印章要素抽取:在材料核验、风控归档中抽取印章区域与关键信息,并与规则/人工复核联动。
4、文档 RAG 数据管线:保留段落、表格、页码与元素坐标,提升检索召回、引用定位与答案可追溯性。
五、生态与竞品
1、生态:PaddleOCR 提供从文档渲染、版面分析到结构化输出的完整工具链,便于落地到批处理与在线服务。
2、竞品:通用多模态大模型与传统 OCR/文档解析方案各有优势;PaddleOCR-VL-1.5 的特点是以较小参数覆盖“真实畸变文档解析”多任务。不同方案的优劣强依赖数据分布与评测设置,建议用自有样本做回归测试再选型。
六、局限与注意事项
1、跨页合并与层级推断存在误合并风险:对版式极不规范、页眉页脚干扰强的文档,需加规则校验与抽样复核。
2、印章识别具有强业务属性:不同地区/单位印章样式差异大,建议补充领域数据与阈值策略。
3、吞吐与成本取决于渲染与推理链路:PDF 渲染 DPI、批量大小、并发与后端实现都会显著影响速度与费用。
4、宣传对比需谨慎解读:若看到与某些闭源通用模型的对比结论,需关注评测集、提示词与输入处理的一致性。
七、项目地址
https://github.com/PaddlePaddle/PaddleOCR
八、常见问题
Q:PaddleOCR-VL-1.5 是否适合弯曲扭曲文档 OCR?
A:官方定位就是面向扫描畸变、透视扭曲与屏摄等场景,并提供不规则区域定位与端到端解析能力;建议用你的真实采集样本做验证。
Q:如何用 PaddleOCR-VL-1.5 构建高精度文档 RAG?
A:优先输出结构化结果(如 Markdown/JSON),保留标题层级、表格结构、阅读顺序、页码与坐标;再按“段落/表格块”切分入库并建立可追溯引用。
Q:跨页表格合并效果不稳定怎么办?
A:在后处理阶段加入一致性校验(列数/表头相似度/页码邻接),对低置信样本走人工复核或回退为“按页解析”。
Q:吞吐达不到官方数据怎么办?
A:检查 PDF 渲染耗时、输入分辨率、batch 与并发、GPU 利用率,以及是否使用官方推荐的推理后端与参数;端到端链路任一环节都会成为瓶颈。
Q:是否支持藏文、孟加拉文等多语种?
A:官方资料给出多语种覆盖并包含藏文、孟加拉文等;上线前仍建议对目标语种做专项抽样验收。