一、摘要
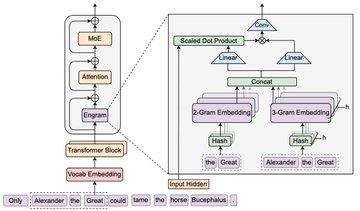
Engram 是 DeepSeek 开源的一种“条件记忆(Conditional Memory)”模块,核心思路是为 Transformer 增加可扩展的查表式记忆原语:把一部分更偏静态的模式/知识以 N-gram 记忆表的形式存起来,在推理时以近似 O(1) 的方式检索并与当前隐状态融合。官方仓库给出的结论是:在等参数、等算力约束下,Engram-27B 在知识、推理、代码、数学等任务上相对 MoE 基线有稳定收益;并且机制分析显示它能减轻早期层对静态模式的“重建”负担,从而把有效深度留给更复杂的推理计算。
二、核心特性
1、O(1) 查表式条件记忆
通过对静态 N-gram 记忆进行确定性寻址与检索,将“知识查找”从密集神经计算中部分剥离出来,降低对计算路径的占用。
2、与 MoE 互补的“稀疏新轴”
MoE 通过条件计算扩容量,Engram 通过条件记忆扩容量:一个偏“算”,一个偏“查”,组合后可以在相同 FLOPs 下更有效地分配模型能力。
3、U 形规模规律用于容量分配
官方给出“计算容量(MoE)—静态记忆容量(Engram)”之间的权衡,并指出存在可指导工程取舍的 U 形缩放规律。
4、机制解释更贴近工程直觉
仓库明确提到:Engram 可能让早期层不必反复重建静态模式,从而把层数与表示能力留给后续更关键的推理过程,可理解为“对推理更有效的变深”。
5、系统效率与可落地性
采用确定性寻址,支持将超大规模嵌入表卸载到主机内存,推理开销增量尽量保持可控。
三、安装
1、准备环境
Python 3.8+,建议使用隔离环境(venv/conda)。
2、安装依赖
按仓库 Quick Start:安装 torch、numpy、transformers、sympy 等依赖。
3、运行演示
仓库提供 engram_demo_v1.py 用于演示 Engram 的核心数据流;该版本会 mock 部分标准组件(如 Attention/MoE 等),重点展示 Engram 模块工作方式。
四、典型用例
1、知识密集型问答与事实回忆
当任务更依赖“稳定知识/固定表达模式”时,查表式记忆可减少模型在前几层做重复模式重建。
2、长上下文中的稳定片段复用
对重复出现的短片段(固定短语、代码样板、常见格式)进行静态记忆命中,减少长上下文下的无效计算。
3、代码与数学场景的模板化结构
在“常见推导套路/代码骨架”较多的任务中,用记忆通道承接更静态的结构,计算通道专注组合与推理。
4、与 MoE 结合的高性价比扩容
在总参数与总 FLOPs 受限的前提下,通过“部分容量放到静态记忆表”来换取更高的有效能力密度。
五、生态与竞品
1、生态现状
目前官方仓库以论文 + 结构图 + 实验图 + demo 为主,适合快速理解“条件记忆”这一新组件,并评估与现有 MoE 堆栈的组合空间。
2、竞品与相邻方向
相邻思路通常包括:RAG(外部检索增强)、kNN-LM/近邻检索、传统 N-gram/缓存、以及各类稀疏注意力/稀疏路由架构。Engram 的差异点在于:它把“可训练的静态记忆表”作为模型内部原语,并强调与 MoE 的容量分工与缩放规律。实际效果仍需结合具体数据分布、训练配方与部署约束验证。
六、局限与注意事项
1、论文细节与复现口径
仓库提供了关键结论与 demo,但大规模训练细节、寻址实现细节与完整消融仍应以论文为准。
2、内存与部署权衡
将巨大记忆表卸载到主机内存虽可减轻显存压力,但会引入带宽、延迟与工程复杂度的新约束。
3、适用性依赖任务形态
如果任务主要瓶颈在“动态推理/组合泛化”而非“静态模式/知识复用”,收益可能不如知识密集型任务明显。
4、与现有训练系统的集成成本
把新模块接入既有 MoE/注意力实现与并行策略,需要评估训练稳定性、吞吐与监控指标(例如命中率、表容量利用率等)。
七、项目地址
https://github.com/deepseek-ai/Engram
八、常见问题
Q: Engram 的核心关键词是什么,解决了什么问题?
A: 关键词是 Conditional Memory、Scalable Lookup、O(1) 查表式记忆、N-gram memory。它试图让 Transformer 拥有“原生知识查找”能力,把部分静态模式/知识从密集计算里分离出来。
Q: Engram 和 MoE 的关系是什么?
A: MoE 通过条件计算扩容量,Engram 通过条件记忆扩容量;两者可互补,形成“算(计算)+查(记忆)”的分工。
Q: 官方机制分析里提到的“更有效更深”是什么意思?
A: 仓库观点是:Engram 减轻早期层对静态模式的重建负担,使网络深度更集中服务于后续复杂推理,从效果上像是“把深度留给关键部分”。
Q: 怎么最快验证 Engram 的工作方式?
A: 直接运行仓库提供的 engram_demo_v1.py,先理解数据流与融合位置;该 demo 会 mock 常见组件以突出 Engram。
Q: Engram 适合替代 RAG 吗?
A: 更适合视为补充方向:RAG 偏外部文档检索与更新,Engram 偏模型内部静态记忆原语与计算/记忆分工;是否替代取决于任务是否需要外部可更新知识与可控检索链路。



