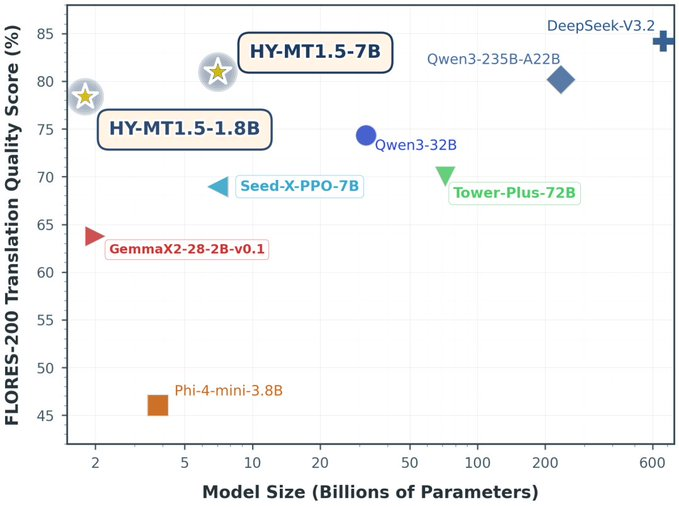
一、摘要
Tencent-HY-MT1.5(HY-MT)是腾讯混元开源的机器翻译模型套件,包含 1.8B(偏端侧/低资源)与 7B(偏云端/高质量)两种规模。官方强调其面向“端侧+云侧”协同部署:端上追求低延迟与低内存占用,云端追求更强质量与更稳健的复杂场景表现,并覆盖 33+ 语言/方言(含部分民汉与中文方言)互译能力。
二、核心特性
1、双模型覆盖端云:1.8B 适配消费级硬件与离线/实时翻译;7B 作为更高质量版本,适合云端批量与高要求场景。
2、速度与资源友好:1.8B 提供量化版本,官方口径为约 1GB 内存占用级别,并给出 50 tokens 级别的低延迟数据(具体以你的硬件与推理框架为准)。
3、生产增强能力:原生支持术语干预(自定义术语对照)、长对话上下文翻译、带格式文本翻译(尽量保持标签/排版)。
4、多语种覆盖:除常见中英日等,还覆盖多种小语种;适用于跨境电商、内容国际化与多语言客服。
三、安装
1、环境准备:建议优先使用官方推荐的 Transformers 版本(仓库示例为固定版本号),并准备 GPU/CPU 推理环境。
2、获取模型:从 Hugging Face 下载对应权重(1.8B/7B 及 FP8、GPTQ Int4 等量化版本)。
3、推理方式:按模型卡/仓库示例构造翻译提示词模板(中外互译、外外互译、术语/上下文/格式翻译模板分别不同),再调用生成接口输出译文。
四、典型用例
1、端侧离线翻译:移动端、桌面端、浏览器插件、输入法/划词翻译等低延迟场景。
2、云端高质量翻译:文档批量翻译、国际化内容生产、多语言知识库构建。
3、行业术语一致性:医疗、法律、金融、软件工程文档等需要“术语不漂移”的文本。
4、多轮对话与客服:将历史对话作为上下文,减少代词指代错误与风格断裂。
5、网页/标记文本:HTML/带标签文本翻译,尽量保持原有结构,便于回填与渲染。
五、生态与竞品
1、生态:提供 GitHub 工程化示例与技术报告;Hugging Face 上提供多种精度/量化版本,便于在端侧与云端选择不同推理成本。
2、竞品参考:开源侧可对比 MarianMT、NLLB 系列、M2M100、SeamlessM4T 等;闭源侧常见为各家翻译 API 或通用大模型的翻译能力。实际选型建议以你的语种覆盖、格式保留、术语一致性与吞吐/延迟指标做 A/B 测试。
六、局限与注意事项
1、指标可迁移性:官方公布的速度/内存数据与效果排名通常依赖特定硬件、量化与推理配置,上线前需在目标设备复测。
2、提示词依赖:术语/上下文/格式翻译需要严格按模板组织输入,否则可能出现解释性输出或格式偏移。
3、小语种与口语体:长尾语种、俚语、强领域文本仍可能出现误译/漏译,建议引入术语表与人工抽检闭环。
4、端云一致性:若端侧与云侧使用不同版本/量化精度,输出风格可能不完全一致,需通过提示词与术语策略收敛。
七、项目地址
https://github.com/Tencent-Hunyuan/HY-MT
八、常见问题
Q: HY-MT1.5-1.8B 适合哪些“端侧翻译”场景?
A: 适合对延迟敏感、设备资源有限、需要离线可用的应用,如移动翻译、IM 内嵌翻译、浏览器划词翻译等。
Q: HY-MT1.5-7B 和 1.8B 怎么选?是否必须二选一?
A: 端侧优先 1.8B,云端优先 7B;也可以端侧先出结果、云端复核/重译,获得更稳的质量与一致性。
Q: HY-MT1.5 的“术语库/术语干预”怎么用?
A: 按官方提供的术语提示词模板,将“源术语→目标术语”的对照作为约束注入,再翻译正文以提高术语一致性。
Q: HY-MT1.5 如何做长对话上下文翻译?
A: 将历史对话作为上下文块输入,使用上下文翻译模板,让模型参考上文语境再翻译当前句。
Q: HY-MT1.5 的格式保留翻译适用于哪些文本?
A: 适用于包含标签或标记的文本(如网页片段/结构化片段)。建议先用小样本验证标签是否能稳定保留,再扩大到批量流程。



